
Often times, we have to work with categorical variables when doing statistical analysis. Categorical variables are those variables that have two or more categories or groups. For example, a variable representing sectors in a stock market could have categories like tech, automobiles, pharmaceuticals, cement, banks etc. These categories of string type may also be needed as part of regressions, in which case, it is important that these categories can be referred to as a number.
We can encode categorical string variables into numeric using the encode command in Stata. This means that each unique category of the variable will be assigned a numerical code. Value labels will also be assigned by Stata automatically to indicate what categories these numerical codes represent. This would then help us understand which numeric value refers to which category of the variable, while also allowing the categorical variable to be used in regressions.
To illustrate how it is done, we will use a dataset that has individual data on the variables shown in the figure below.
Related Article: How to Convert String variable into numeric in Stata
When we browse the data, we see that this is an individual-level dataset. We also observe that the age group variable ‘age_grp’, ‘race’, and ‘sex’ are categorical variables. Each individual is part of one category for each of these variables. Note also that since these categorical variable values appear in red, they are strings.
Download Example File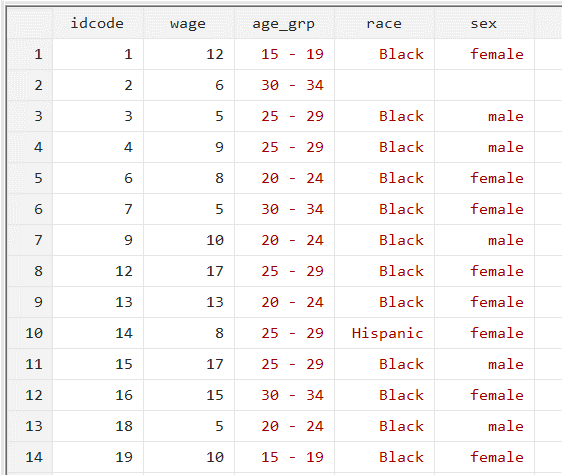
Now, what if we wanted to evaluate the effect of age on a person’s wage? Let’s run a regression.
regress wage age_grp
We get the following error:

Since categorical variables need to have an i. prefix in regressions (so that we get a coefficient for each category), let’s alter our command.
regress wage i.age_grp
Once again, the following error message is returned:
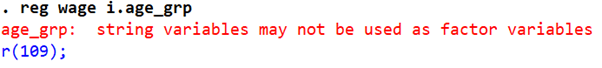
‘Factor variable’ refers to categorical variables. Since ‘age_grp’ is a string variable, Stata cannot use it to run regressions. We must encode it into numeric type.
This is where the encode command comes in Stata.
What encode does is assign a numeric value to each category of a variable. For example, the ‘sex’ variable has two categories, ‘male’ and ‘female’. The command will assign the value of 1 to one of these categories, and the value of 2 to the other. If there are more categories in a variable, they will further get assigned 3, 4, 5…
Encode a Categorical Variable Using Stata’s Menu
To encode a variable using Stata’s menu, the following steps can be followed:
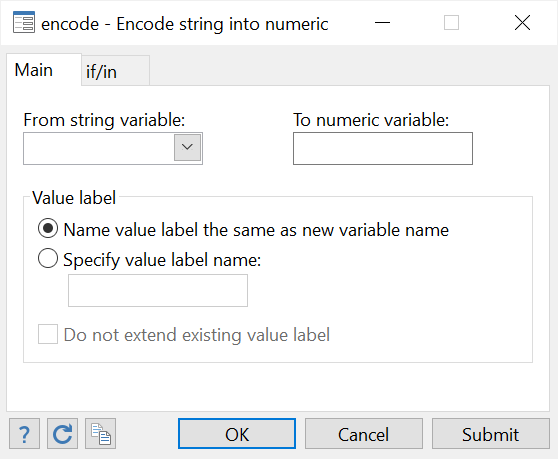
Data > Create or change data > Other variable-transformation commands > Encode value labels from string variable
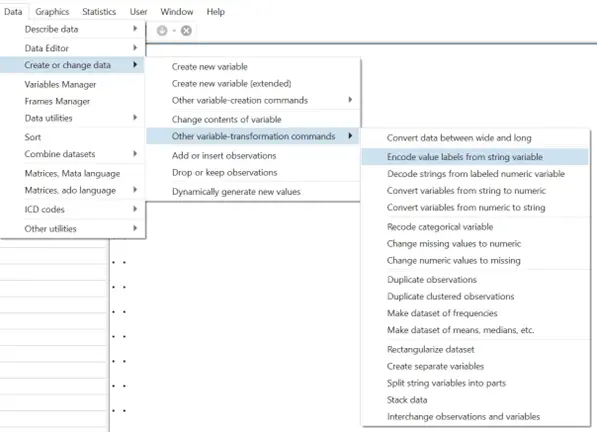
In the dialogue box that opens, add the string variable that you want to convert. Then add name you want to give to the new, encoded variable. You can also specify value label names if needed.
We will explore the encoding of categorical string variables into numeric ones using the encode command.
Convert Categorical String Variables to Numeric: The encode Command in Stata
The general syntax of the encode command is:
encode string_variable, generate(new_numeric_variable)
Let’s encode the ‘age_grp’ variable and name the new numeric variable as ‘encode_age’.
encode age_grp, generate(encode_age)
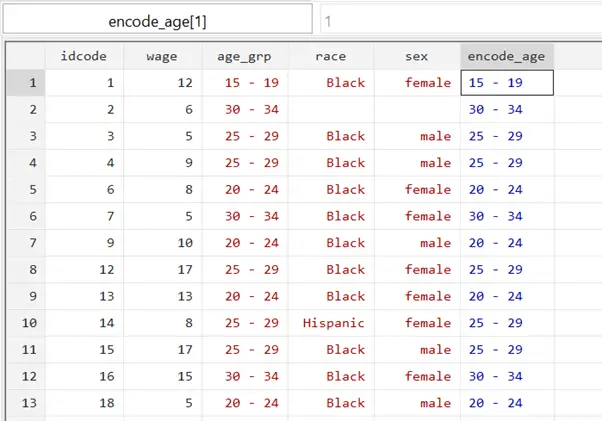
The new variable is generated.
Related Article: How to Combine Categorical Variables in Stata
The variable displays the same category names that were there in the original ‘age_grp’ variable. But note that it is blue in colour, and displays a ‘1’ in the bar on the top. This 1 indicates that the category of ‘15-19’ is encoded with 1. You can click on other categories of this variable in the browse window to see what number they have been coded with.
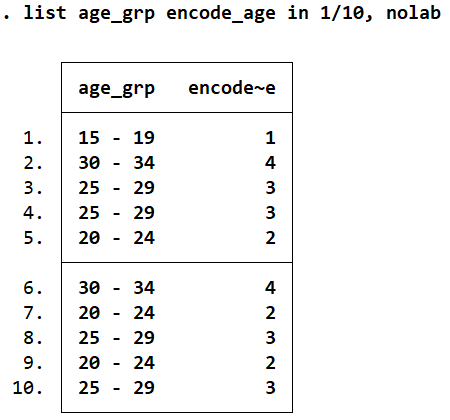
If we use the list command to display the first ten observations for both variables, we note the same again.
list age encode_age in 1/10

The same command, when repeated with a nolab option, returns us the numeric value that the ‘encode_age’ variable has (the age ranges displayed above are the labels for these numeric values).
list age encode_age in 1/10, nolabel
You can also check the categories and their numeric code by using the codebook command.
codebook encode_age
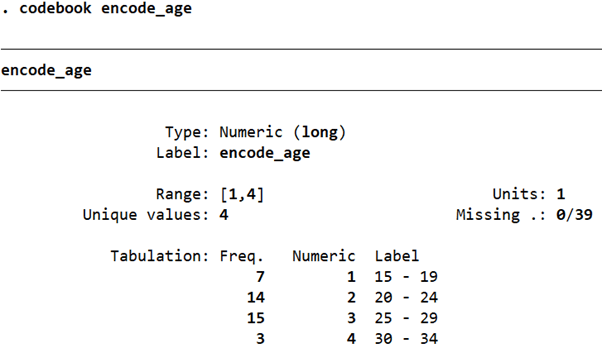
As can be seen in the ‘Tabulation’ section, there are four numeric codes (1-4) and each of them represents an age range. The corresponding age range for each numeric code is given under the ‘Label’ heading.
The regress command can now be run again with the ‘encode_age’ variable.
regress wage i.encode_age

We now get coefficients for each category of age. Remember that whenever we run regressions with a categorical variable that has n number of categories, the regression output will always display coefficients for n-1 categories. Reporting all four categories will result in the problem of multicollinearity. The coefficient for the omitted category (also called the base category) can be ascertained from the constant/intercept term, ‘_cons’.
Assign Custom Labels When Using encode command in Stata
The encode command always assigns numeric values starting from 1 in Stata. But when we want to run regressions with binary/dummy variables, it is important to have the variable coded with 0 and 1. Let’s see how Stata encodes ‘sex’, a binary variable.
encode sex, gen(gender)
codebook gender

The category for female is assigned the value of 1; and male, the value of 2. The empty values were coded as missing. We want the female category to be coded as 0, and the male category as 1.
In order to do that, let’s create a label called ‘sexlabel’ which will store these custom codes and labels.
label define sexlabel 0 “female” 1 “male”
This command won’t produce any output. It just defines the label and the value labels it contains in Stata’s memory. You can confirm that the label has been created either through the Variable Manager using the menu option: Data > Variable Manager > Manage (in front of the ‘Value label’ field). You can also list out all the labels in your dataset using the command:
lab list
Now, the encode command can be used with the option label() which is used to indicate the way each category is to be labelled when the variable is encoded.
drop gender
encode sex, generate(gender) label(sexlabel)
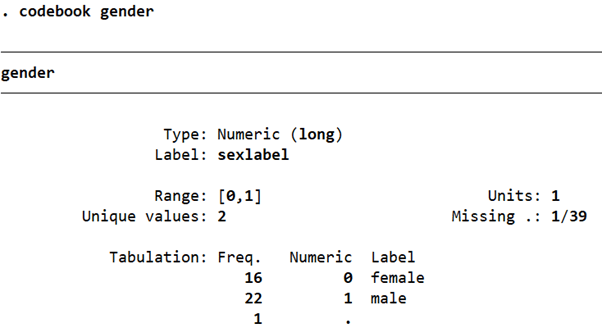
The variable is now coded correctly in the manner we wanted and as specified in the label called ‘sexlabel’.
Note also that when defining labels, case-sensitivity needs to be kept in mind. If you were to label the values of 0 and 1 with ‘Female’ and ‘Male’ instead of ‘female’ and ‘male’, Stata won’t be able to use this label with the ‘sex’ variable correctly. The string values in this variable are in all lower case. Stata will not assign 0 to “female” in a variable if you wrote “Female“ when defining the label (“female” != “Female”).
Not Encoding if Value Labels Are Unspecified in Stata
If we define a label for a variable but only add value labels for some categories while omitting others, we can tell Stata to not encode that variable. This is done using the option noextend. This option tells Stata that if some values present in the variable are absent from the label defined for it, then the variable should not be encoded, by using encoding command in Stata.
For example, for the ‘race’ variable, our data has three categories: White, Black and Hispanic.
tab race
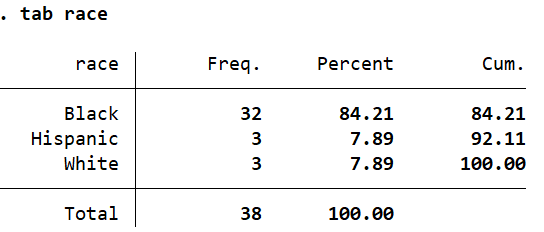
Let’s define a label called ‘racelabel’ that has values for only two categories, and then use this label to encode the ‘race’ variable (with the incomplete list of value labels) while using the noextend option.
lab def racelabel 1 ”Black” 2 “White”
encode race, generate(encode_race) label(racelabel) noextend

Because a value label for the Hispanic category was not defined in the label that we are trying to assign to ‘encode_race’, Stata is not encoding the ‘race’ variable at all. This is because we used the noextend option.
Reducing The Size of the Data Using encode command in Stata
Data with a lot of string variables tends to be large in size as strings take up more storage than numeric data. If a dataset has repeating strings like a person’s name, company names, sector names etc., the data size can end up being very large. The data size can be reduced by using encode command in Stata.
As can be seen from the Data panel on the bottom right, the current size of the dataset is 1.22K. Let’s encode the ‘race’ variable correctly, and drop all the string variables.
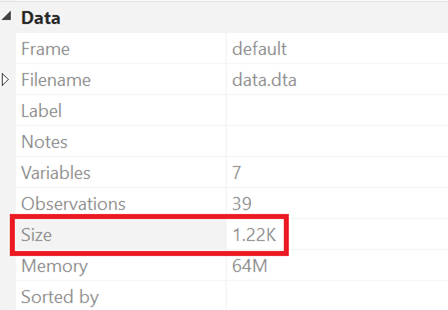
encode race, gen(encode_race)
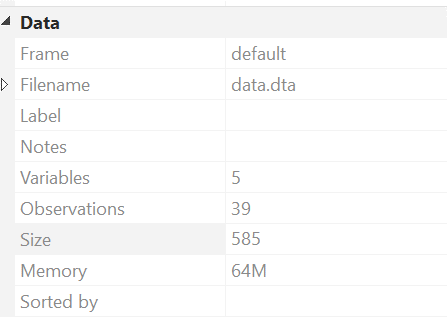
drop age race sex
The data size now is only 585 bytes, a reduction of almost 50%.
An important thing to note about the encode command is that it should not be used to encode a variable that contains numbers which are stored as strings. When numbers are stored as strings, the command destring is used to turn the string variable into a numeric type.
Converting Numeric Data to String in Stata – The decode Command
If we want to convert numeric data to string type, the decode command is used in the same manner that encode was used.
decode encode_age, generate(string_age)
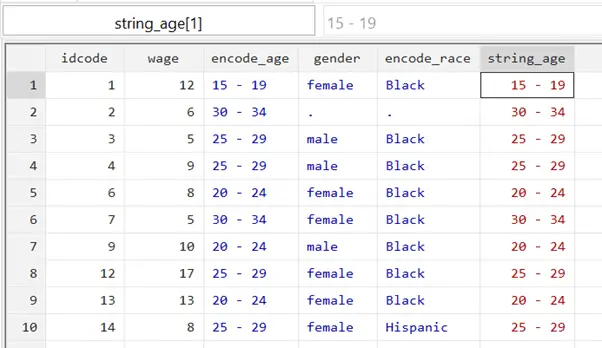
We can also specify the number of digits that the string variable should retain from the numeric variable using the maxlength() option. The number of digits is specified in the brackets.
Let’s drop the ‘string_age’ variable and decode ‘encode_age’ again with a maximum length of 2 characters to be retained.
drop string_age
decode encode_age, generate(string_age) maxlength(2)
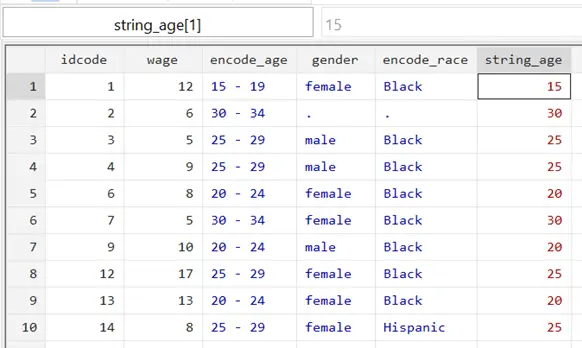
As can be seen, only the first two characters of ‘encode_age’ make it to ‘string_age’ if we specify so in the max length() option. This new variable may look like it is of numeric type because it only contains numbers, but it is a string variable. In addition to the fact that we just generated it using decode, it is also red.