There are different kinds of variables that can be observed in the data, including numeric, non-numeric, binary, and so on. Stata usually deals with numeric variables having discrete or continuous numbers in them. However, sometimes we have to deal with data where observations are non-numeric and contain some characteristics. These kinds of variables, having characteristics or non-numeric data in them, are called String variables, and the data which contains these variables is called String data.
String variable in Stata
Let’s simply run a regression in the Stata and identify the error that the presence of string variables in Stata could cause. First, import the following Data in Stata.
Download Example FileOnce the data has been imported, run the regression command, and regress close variable on high. Although theoretically, it does not make any sense, this is just to demonstrate an idea.
regress close high
The following result will be generated, which shows an error that no observations are found in the data.

Related Article: Using the Encode Command In Stata to Convert String Variable
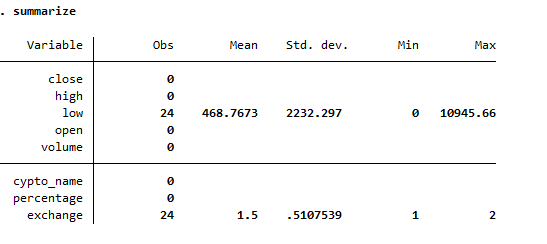
However, if we look closely on the properties window of the variables, we can see that 24 observations are found in the data set.
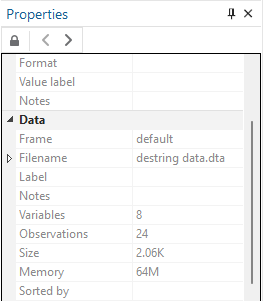
To further verify that observations are found in the data set, we can summarize the data, and check whether the error shown in regression results is correct or not. To summarize the data, use the following command
summarize
In the results shown below, results shows that the variables we used in regression doesn’t have any observations and only two variables i.e. low and exchange has 24 variables.
The data editor can check whether the variable’s data is missing values, as shown in summary results. As shown in the image below, there are observations in the data editor, for all the variables, including the variables used in the regression.
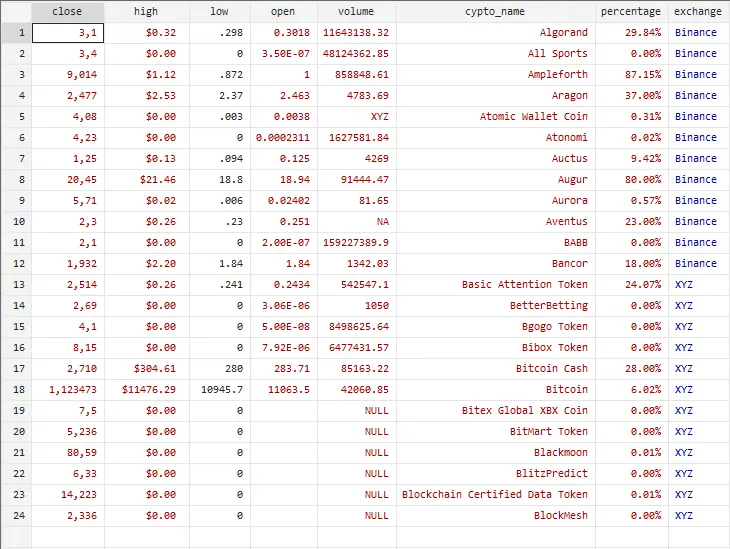
However, the error in regression could occur because of the type of observations in the data. As seen in the above image, there are different types of observations in the variables. There are characters (,) present in the close variable, and some other variables have non-numeric data also. To identify which variables are valid and ready to use in the Stata, we can also differentiate them through the colors.
In the window editor, there are variables with three types of colors; black, red, and blue. The variables in black are recognized by Stata as numeric data, ready to be used. For example, the color of the “low” variable data is black because its type is float. Float represents that the data is numerical. The variables having values in red, however, are non-numeric and are recognized as string variables by Stata. We can also check that by clicking on the high variable and looking at its properties, and we can verify that its type is “str12,” i.e., a string variable.
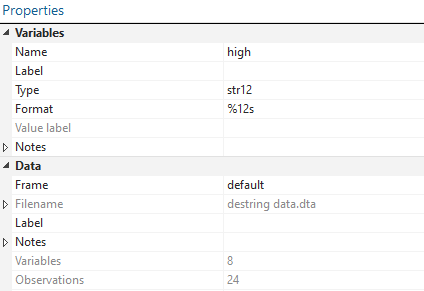
Similarly, the blue color is the categorical data coded as 0 and 1 or 1 and 2. In our data, the category Binance is coded as 1, and the category XYZ is coded as 2. So the variables in blue are valid and ready to be used in Stata. The type of this data is long. Long is a type for the data in the text, but has a numerical value.
However, relying on color scheme in Stata isn’t preferred. Because if you change the theme of the Stata into dark, these red, blue and black colors will be replaced by yellow, blue and white. This is shown in the image below.
So instead of relying on the colors of variables, it’s more convenient to click on the variable and check the type of variable by its properties from the properties window.
Convert data of String variable into numeric in Stata:
Some of our variables are in the form of String variable in Stata, and are thus not valid to be used in Stata. That is why Stata is giving an error whenever we try to perform a function on it. The solution to this problem is by converting the String data into numeric data.
To convert the string data into numeric in Stata, there are two ways to do that. One is by using manual window option, and the other is by using Command option.
To use the first option, click on
Data > Create or Change Data > Other variable transformation commands > convert variables from string to numeric
Another way to convert string data into numeric is by using the destring command. To find out the usage of the destring command, write the following command.
help destring
The following window will appear that shows us how to use the destring command.

In the above manual, the destring command is used with a list of variables that need to be converted from string to numeric variables. Further, you can either generate the new variables that are numeric or have the string variable replaced with a numeric variable in Stata. To replace the string variables with numeric variables without generating a new variable, we can use the following command
destring, replace
Note that, in the above command, it has not been specified which variables are to be replaced from string to numeric, so it tried to convert all the variables. However, due to reasons discussed below, only one variable open has been converted into the double and the rest of the variables are still in string form. You can verify this by looking into the data view. Here, double is one of the types of numerical data. You will notice that the missing values of the variable open will be replaced with a dot (missing character).
Related Article: Using Sort command in Stata

If we want to convert certain string variable to numeric in Stata, we need to specify those variables and run the command.
destring close, replace
The variable close has been converted into numeric variable.
We can also remove a specific character from values of a variable. E.g. in the provided data set, the variable “high” is in the dollar and has a $ character with the variable.
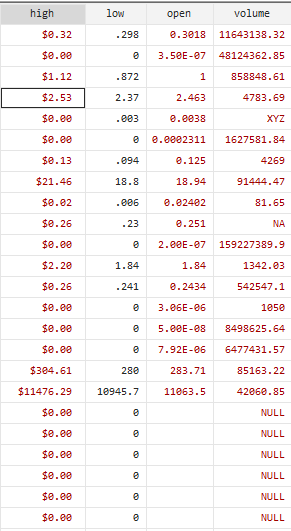
To remove the $ sign and convert it to a numerical variable, the below command will be used.
destring high, replace ignore ("$")First, we will write the destring command, then the variable name followed by replace option to instruct if we want to replace the existing variable. Lastly, Stata has to be instructed to remove the dollar sign from the data by using the ignore option. The variable high will be converted from string to numeric form, with all dollar signs removed from the values.
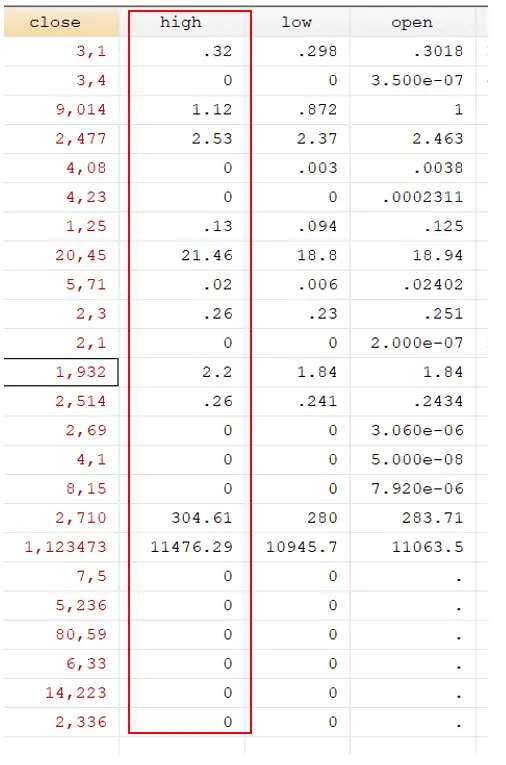
There is another variable named volume in our data that contains a different non-numeric value, “Null.” The ignore option would not be appropriate in this case because “null” is not the only non-numerical value. This variable also contains two more non-numerical values, i.e. NA and XYZ. Therefore, in that case, we will use the “force” option at the end of the command.
To use the force option, the following command will be used:
destring volume, replace force
You will notice that force will keep the numerical values and convert all the non-numerical values into the missing values.
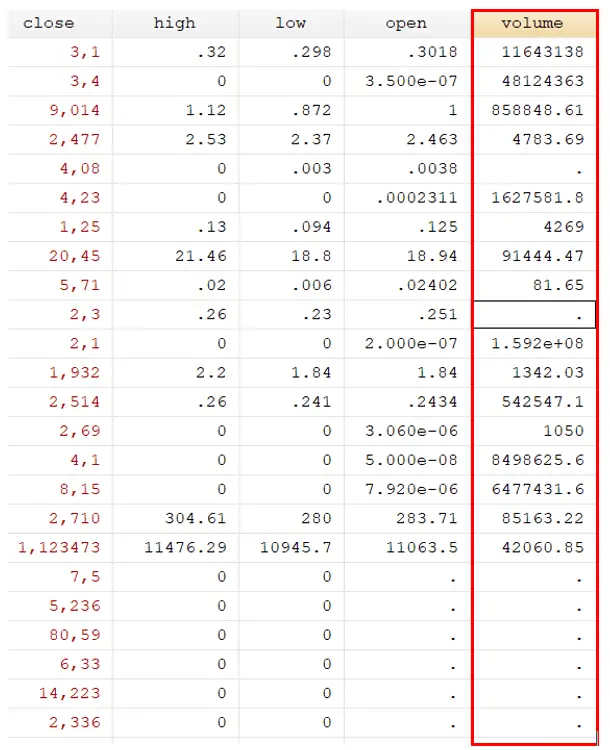
destring volume, replace force
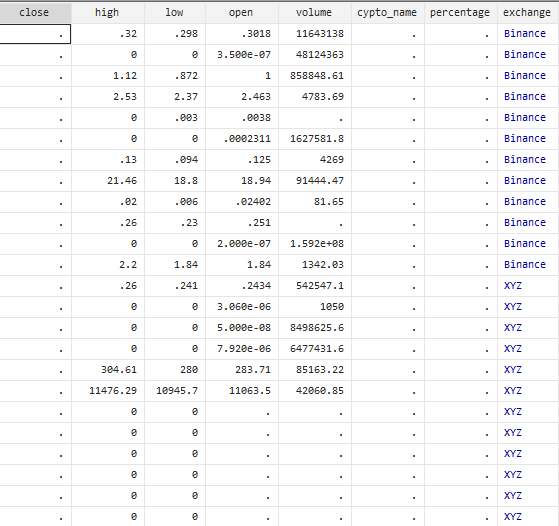
However, this force option should be used with caution. That is because if we don’t specify variables with the force option, it will convert all the non-numeric values or those values that contain characters in them into missing values. For instance, let’s use the force option to convert all variables into numeric variables using the following command
destring, replace force
Now, if we have a look at the data editor window, we can see that all variables having characters in them, including close, crypto_name, and percentage, have missing values in them. This could lead to bigger errors in the data because instead of converting non-numeric to numeric variables, Stata generated missing values. Thus, the force option should be used cautiously and specified with variables having non-numeric values.
Now move to another variable percentage. The values of the percentage variable have % character with them. However, there is a catch. If we ignore the percentage sign, Stata will just remove the percentage sign, and retain the value as before. But, as the percentage of a number is not same as the number, i.e. 29.8% equals 0.298, so what we want Stata to do is to convert number into fraction, along with removing the percentage sign. For that, we use the following command.
destring percentage, replace percent
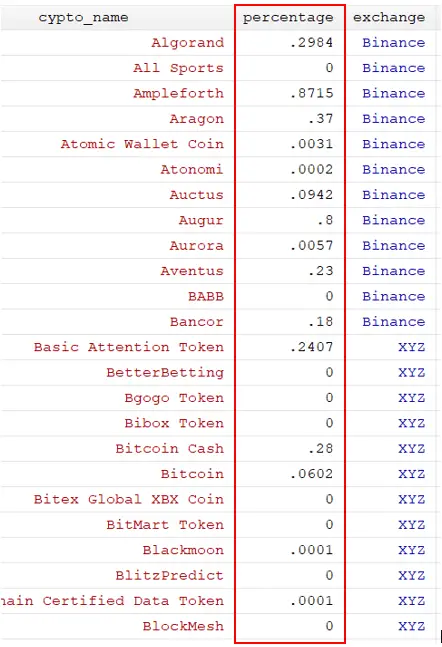
This will convert all the percentages into fractions.
Similarly, some variables “close” have non-numeric values in the form of commas. These commas will be considered non-numeric, and Stata wouldn’t perform numeric operations on them. In some datasets, these commas could be misplaced instead of fractions or decimal points. To do so, we now need to specify to Stata that it should replace commas with decimal points so that the following command will be used.
destring close, replace dpcomma
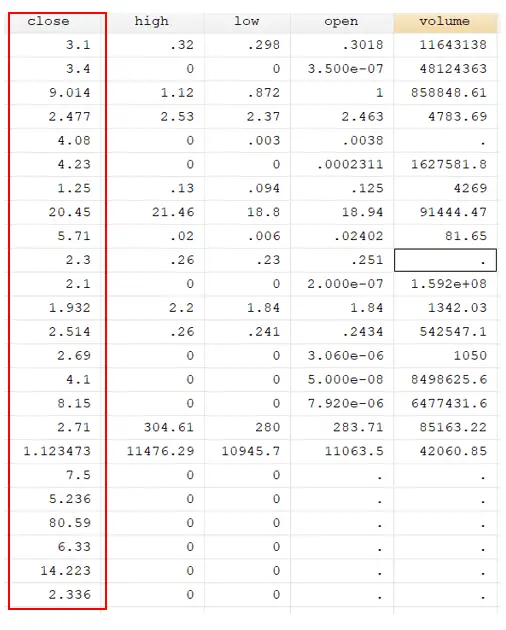
You will notice that the commas from the close variables will be removed, and values will be converted into decimals.
Generating new Variables:
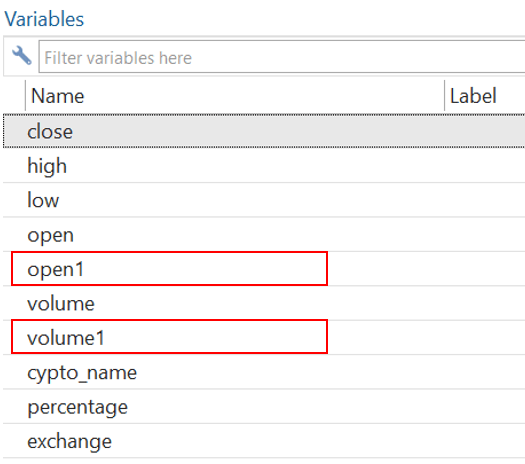
Sometimes, the requirements of the data are such that we have to generate a new numeric variable from a string variable instead of replacing it. In such cases, new variables can be generated from Stata using the string variables. Our data have different string variables, but most of them are replaced with numeric variables using different commands. However, we generate two new variables from the string variables; open and volume. These newly generated variables will be in the form of numeric variables. But the previously present string variables will also be retained and not replaced by new variables.
To generate new variables for open and volume, the following command will be used
destring open volume,generate(open1 volume1) force
This command will destring the open and volume variables, and newly generated variables will be numeric.