
The bulk of data used in Stata for analysis purpose is mostly found in random observations. This data usually don’t follow the ascending or descending sequence. However, if we arrange data in a certain manner, it becomes easy to handle it, especially when it is in bulk. Note that, here, we are talking about arranging data or observations in the Stata, not variables in the Stata. Variables can also be arranged and relocated either at the start of the list of variables or at the end of the variable list. However, this post is about arranging data of different variables in Stata. The data can be arranged in stata by using the sort command.
Sort Command in Stata
The data can be arranged into ascending or descending order in Stata by using the sort command in Stata. For instance, if you wish to arrange prices of cars in a data, and the arrangement of prices should be from the lowest price to the highest price (ascending order), the sort command will be used.
Let’s visualize it by importing the data using the following command:
sysuse auto, clear
The data will be imported and the observations of all variables show a random arrangement of observations.
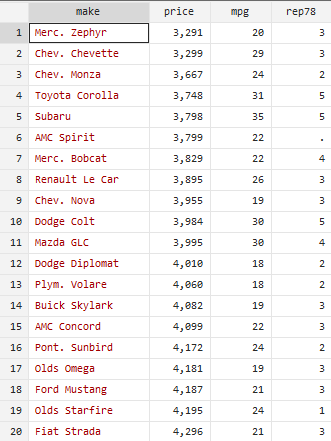
Now we wish to arrange the observations of a variable, say price. For this purpose, sort command will be used. Note that using the prefix sort can only arrange the data in ascending order. To arrange the data of car prices, we will use the following command
sort price
This will arrange the observations of car prices in an ascending order. However, the observations of rest of the variables are not sorted. This happened because we didn’t use the sort command for them.
Related Article: Using Rename command to rename Variable in Stata
Using Sort command for Sorting data of multiple variables:
Previously, we used sort command for a single variable, i.e. price. However, the data or observations of multiple variables can also be arranged using the same sort command. There are no complexities in arranging the observations of multiple variables. It will take only the sort command in Stata to arrange data of multiple variables. For example, if we wish to arrange data of car prices and whether cars are produced domestically or in a foreign country, the two variables named price and foreign will be sorted.
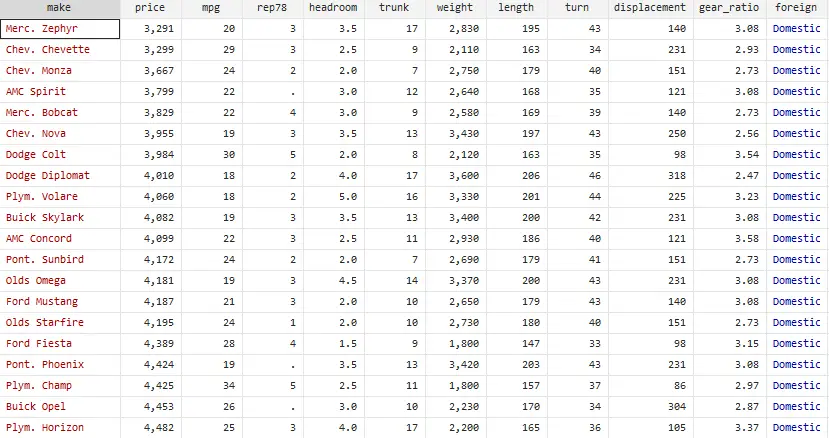
sort foreign price
Now what sort command did is it arranged the observations in foreign variable in an alphabet ascending order. As the foreign variable has only non-numeric observations, so those observations are ascended alphabetically. The domestic cars come first and as we also sorted the price of cars, so price of lowest domestic car comes first. The whole data cannot be captured in an image. However, if you run the commands in the Stata, you can verify that lowest price of domestic cars is $3291 and highest price is $15906.
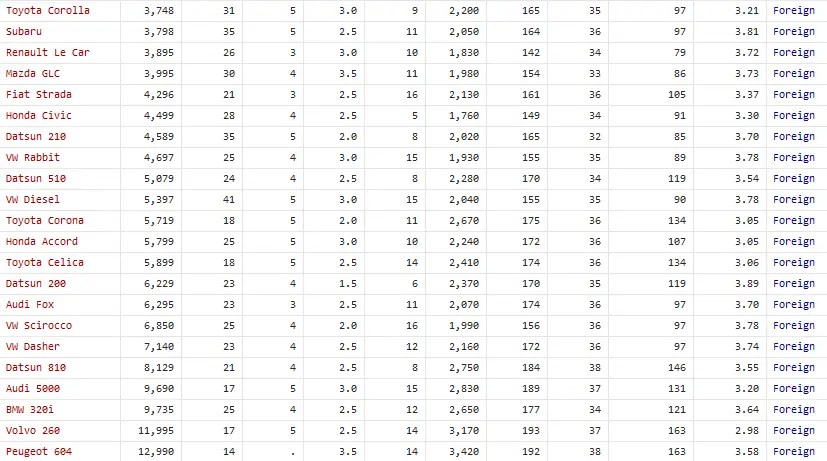
Similarly, after the observations of domestic cars, the prices of foreign cars are ascended in the data. The lowest price for foreign cars is $3748 and highest price is $12,990, as shown in the image below.
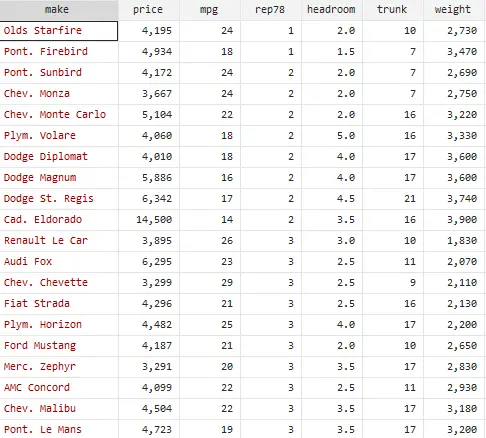
Let’s repeat the process by using a different set of variables and arranging their data in ascending order. Using two variables named rep78 and weight, which represent the times a car is repaired and weight of cars respectively, we can use the sort command in Stata to arrange their observations.
sort rep78 weight
As shown in the image below, observations are arranged in ascending order and data of variables is arranged perfectly.
Data of any number of variables can be arranged using sort command in Stata. There is no limit for number of variables that can be sorted using this command.
Using Stable Option in Stata
Before diving into the stable option, re-importing the data will help us understand the stable option clearly. Using the following command to import data
sysuse auto, clear
The recently imported data has not any kind of ascending or descending order. Now, to sort the repair variable named “rep78”, we will use the following command
sort rep78
Now, as seen in the image below, there are 2 cars having been repaired once. But how it is decided that which car should come first? Similarly, the cars having been repaired 2 times, as evident from the row 3 to 10, are arranged randomly and no sequence is followed.
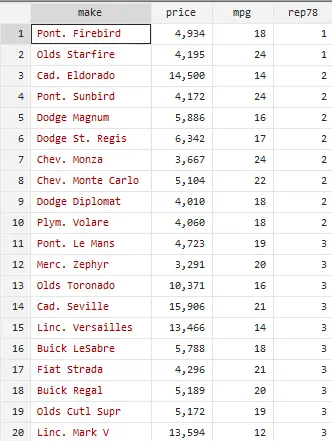
As in 3rd row, the car having repaired twice is “Cad. Eldorado” and has a “14500”. But if we import data again, using the sysuse auto, clear command, and again sort the rep78 variable, the car in 3rd row will be different. So the arrangement in the groups of cars is not sequenced properly.
To understand it further, let us use the help window in stata. Using the following command, we can see a help window appear in the stata.
help sort
To read the menu completely and understand the stable option better, click on “view complete PDF manual entry”.
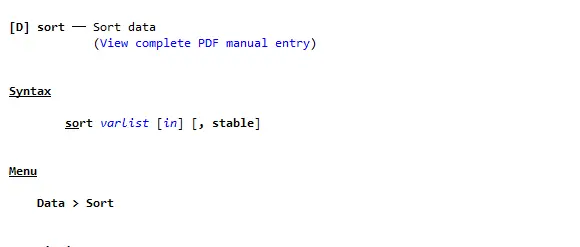
A window will appear, and you should scroll down the screen, up to the option heading. It clearly shows that if we run the sort command without using stable option, we will get different results for “b” variables. What that means is, if we sort the variable “a” lets say rep78 in our case, the values of variable “b” say price in our case will be arranged differently and randomly in each case.

To prevent this from happening, we use the stable option. The following command will be used to sort the data in the stata.
sort rep78, stable
Related Article: Stata Command Syntax: How To Write Commands in Stata
Sorting data in descending order
Using the prefix of sort command in Stata can only arrange the observations in descending order. To arrange data in a descending order, we need to use the gsort command in Stata. However, the catch here is that, both sort and gsort command will arrange the data in an ascending order.
gsort price
In order to arrange data in descending order, gsort command will be used with a negative sign “-“ before the variable we wish to arrange. This will arrange data in such a way that highest observations come first, and lowest observations follow them. Thus, to order data in descending order, gsort command with the negative sign is used. For instance, if the price variable is to arranged in descending order, the following command will be used.
gsort –price
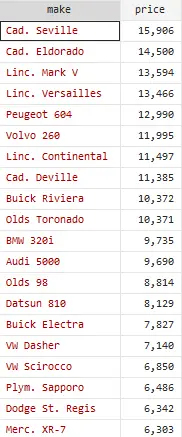
Similarly, if we wish to use two variables, but the data of one variable needs to be in ascending order but the data of the second variable needs to be in descending order, gsort command will be used. Take an example where we want to arrange variable rep78 in ascending but price of cars in descending order. The following command will be used.
gsort rep78 –price
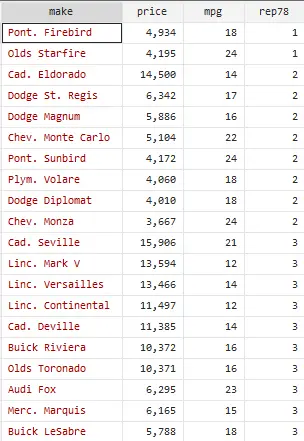
In the above image, you might notice that car prices are not arranged in a perfect descending order, but as we are using two variables here, their observations need to be in parallel. Note that as there are two variables here, one is a number of times a car is repaired i.e. rep78 and the other is price of the cars, keeping in view the number of times a car is repaired.
So as shown in the image, the data of rep78 variable is arranged in ascending order, the price of the cars is arranged in descending order but in parallel with the rep78 variable. Simplifying it, the group 1 where cars are only repaired 1 times, as shown in rep78 column, the price of these cars is arranged in descending order. Similarly, in the next group, the cars are repaired 2 times and their prices are arranged in descending order.
Generating ID in Stata
ID is generated in Stata to make sure that no observation combination appears more than once in the data. To create such an ID for variable rep78, following command will be used.
gsort rep78, generate(r)
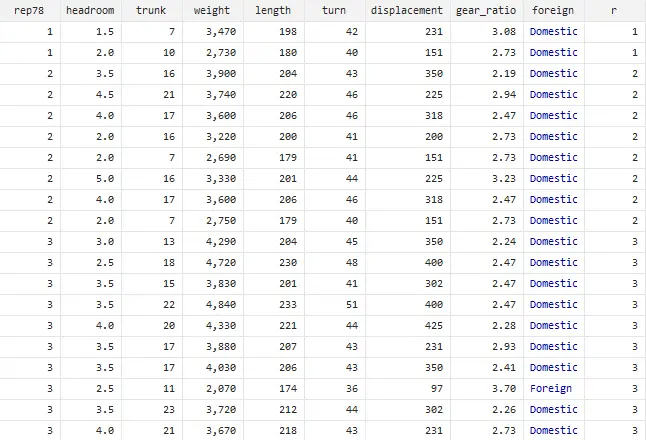
“r” is the name we are giving to the new variable need to be generated. The new variable r will generate the exactly same values as given in rep78 variable, in an ascending order.
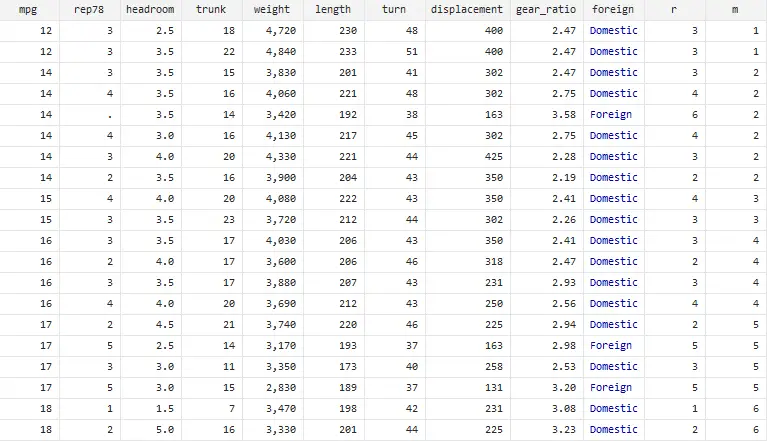
To demonstrate it further using another variable, let’s create an id for the variable mileage (mpg) and naming the new group “m”, use the following command
gsort mpg, generate(m)
Order the Missing values in Stata
In certain variables, some of the observations are missing. Usually these missing observations go at the end of data, even when you arrange the data in ascending or descending order. However, if for some reasons, we wish to arrange these missing values and need them to be present at the start of data, we can use the gsort command for that purpose.
For the variable rep78, we have missing values at the end of the column. If we need these values to be present at the start of the column, the following command will be used.
gsort –rep78, mfirst
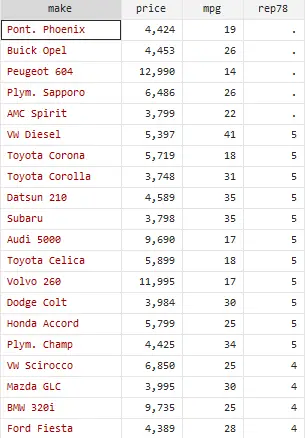
Note that as the rep78 observations are arranged in descending order, the negative sign is used. Similarly, if we want the observations to be arranged in ascending order, the same command will be used but now without negative sign. The missing values will now go to the end of the table.
gsort rep78, mfirst