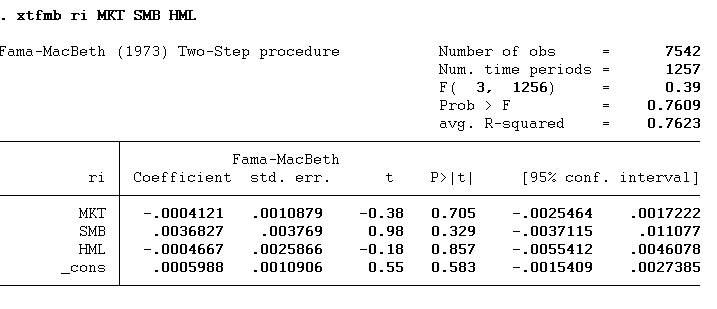
Fama and MacBeth’s regression was proposed in 1973. The Fama-MacBeth (1973) regression procedure is instrumental, especially when dealing with datasets that have more cross-sectional data as compared to time-series data. So, the first question we get to ask is why use fama-macbeth regression. A notable advantage of this procedure is that it provides standard errors corrected for cross-sectional correlation, which is crucial for obtaining reliable inference statistics. This characteristic is particularly beneficial in scenarios where the cross-sections are significantly larger than the time periods available for each cross-section. Composing the analysis into two stages—first looking at time-series regressions for each cross-section and then conducting cross-sectional regressions for each time—provides a framework that efficiently handles the cross-sectional correlation in the data. This method thus yields more reliable and insightful results when the dataset has a rich cross-sectional dimension but a limited time-series dimension.
Procedure of Fama and Macbeth Regression
Step 0: Perform Time Series Regression
Under this step, we will run time series regression. For example, if we have done portfolio construction and we have 10 portfolios, each with multiple years of data. We will run the portfolio or asset return against the risk factors and get the regression coefficient. There will be ten different coefficients if we have ten cross-sectional data points. This step is termed ‘Step 0’ as it serves as a preparatory phase before embarking on the two-step Fama-MacBeth regression procedure. The Fama-MacBeth procedure traditionally consists of only two steps, rendering the initial time-series regression as a preliminary or ‘zero’ step, essential for procuring the necessary data for the ensuing steps of the analysis.
Step 1: Perform Cross-Sectional Regression
Under this step, we will run cross-sectional regression, in which the portfolio and asset returns are regressed on the regression coefficient obtained in Step 0. We will use cross-sectional regression for each day. If we have 100 days of data, we will perform cross-sectional regression 100 times. We will get the beta coefficient in this step.
Step 2: Average the Coefficients
In this final step, the coefficients obtained from the cross-sectional regressions in Step 1 are averaged over all the time periods.
As we discussed already, steps one and two are the actual steps of the Fama and Macbeth regression; that’s why all the Stata packages used to perform Fama and Macbeth regression will only perform steps 1 and 2. It assumes that step 0 is already done. Another thing that must be remembered is that Fama and Macbeth regression cannot be used with cross-sectional invariant variables. For example, the data of GDP or inflation for a single country does not vary from firm to firm.
Manual Method Fama and Macbeth Regression
Download Code and DataOnce we have understood the theoretical concept, let’s dive into the limitations and challenges of applying the Fama and Macbeth method.
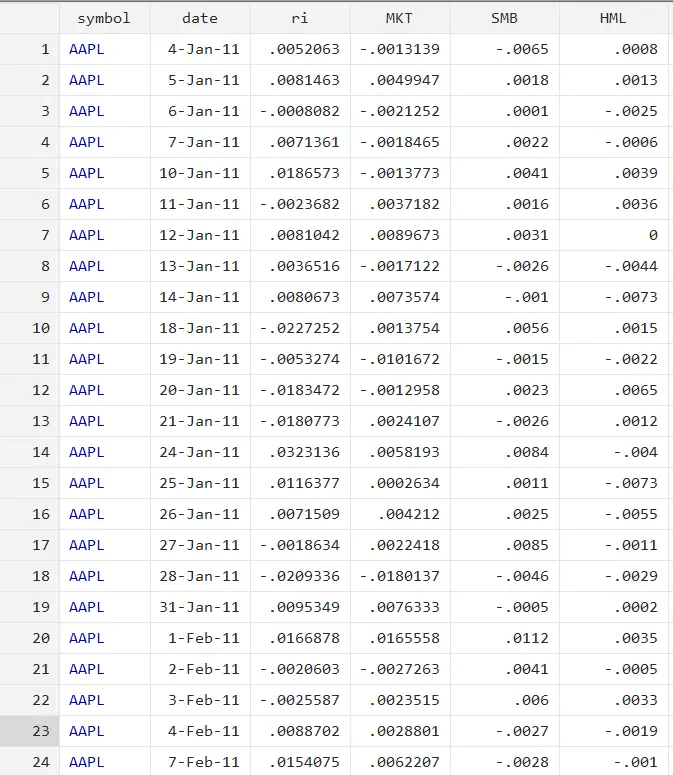
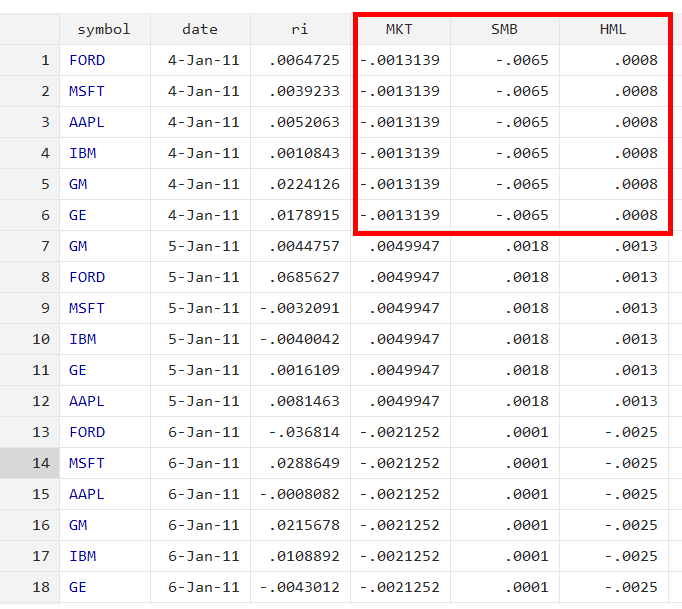
First we will look into the manual way of doing Fama and Macbeth regression so that we can develop a better understanding. The data we will use in this article is shown below. The dataset comprises daily returns of companies, market returns, SMB, and HML data (the three factors from the Fama and French three-factor model).
Step 0: Perform Time Series Regression
In step 0, we will perform the time series regression using the statsby command. The command will run the regression separately for each symbol (for example, AAPL, FORD, and so on).
statsby, by(symbol) saving(step0): regress ri MKT SMB HML
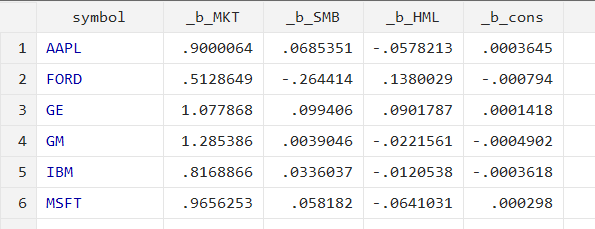
statsby is the command, and by is an option for statsby that specifies the variable by which to group the data or the variable for which it would perform separate regression. In this case, it is grouped by the symbol variable. saving is another option for statsby that specifies the name of the new dataset to create, which in this case is step0. The option will save the beta coefficient for each symbol in a single file. regress is the command for the regression analysis in Stata. ri is the dependent variable, and MKT, SMB, and HML are the independent variables. The new Stata file will be generated and named step0.dta upon running the above command. The figure below represents the beta coefficient for each company saved in file step0.dta.
After this step, we will merge the step0.dta file with the main data file using the below command:
merge m:1 symbol using "step0.dta"
After running the above command, the four new variables will be created in the main file, each company’s beta coefficient.

Step 1: Perform Cross-section Regression
In the next step, we will perform cross-sectional regression using the below command. In this step, we will regress the return in each time period on the beta coefficients of MKT, SMB, and HML obtained in step0.
statsby, by(date) saving(step1): regress ri _b_MKT _b_SMB _b_HML
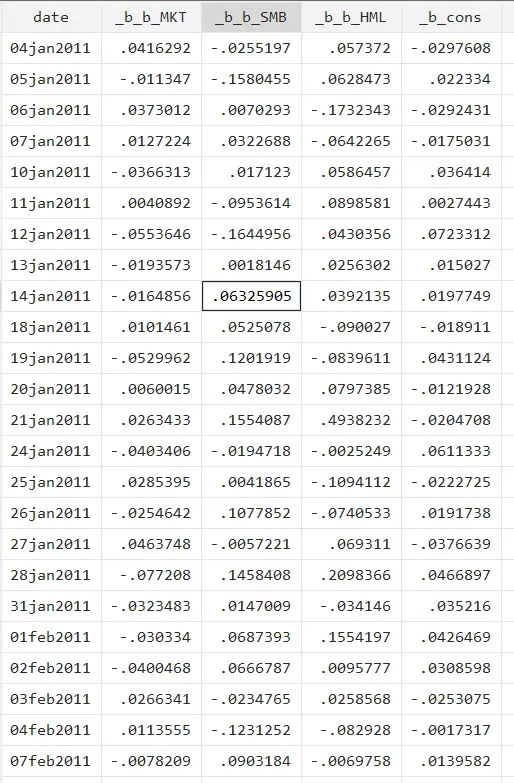
This time, in the by option, we have to use the date variable because we wish to perform cross-section regression, i.e. for each time period we want to perform a regression separately. We will save these results in the step 1.dta file. Let’s open the saved file and view the data.
use step1.dta, clear
Step 2: Average the Coefficient
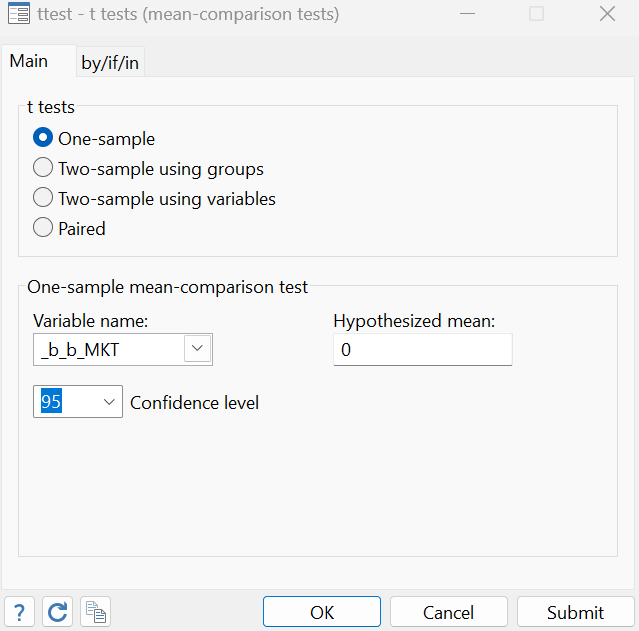
In step 2, we will take the average of each coefficient. This will be done with the help of the t-test. The path for the t-test is explained below:
Statistics > Summaries, tables and tests > Classical tests of hypotheses > t-test (mean comparison test)
Or you could have used the following command to perform the above t-test:
ttest _b_b_MKT == 0 ttest _b_b_SMB == 0 ttest _b_b_HML == 0
The results are given below:



Let’s look into the fama-macbeth regression interpretation. We will look at the t value and p value. According to the findings, the mean is not statistically significant. The null hypothesis is that the impact of factors on expected return is equal to zero. As p-value is greater than 0.05, hence we conclude that these factors cannot explain stock return.
ASREG Method
Instead of performing Fama Macbeth manually, we can simplify the process using the asreg command. ASREG is the Stata user-written command that can perform the Fama Macbeth Regression. This command first needs to be installed using the below command:
ssc install asreg
After this, we must tell Stata we are using panel data. We can do this by using the below command:
xtset symbol date
This method also includes three steps. The steps are explained below:
Step0: Time-series Regression
The step 0 will be the time series regression that will be performed using the below command:
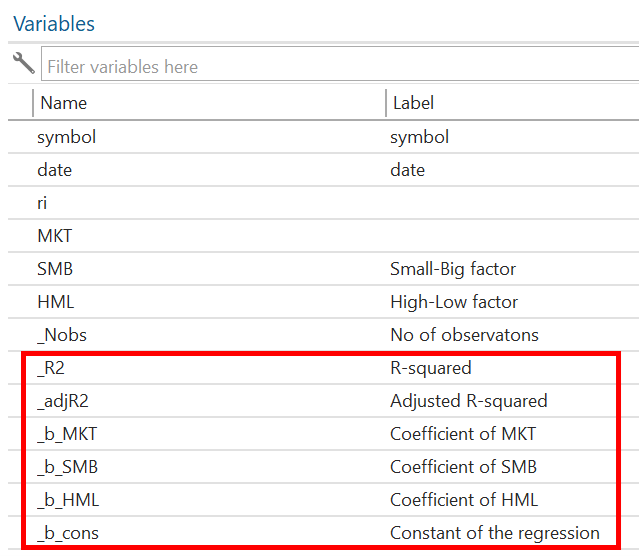
bys symbol: asreg ri MKT SMB HML
bys command has been used to tell Stata that we want to perform the regression separately for each unique value of the “symbol” variable. asreg is the command for Stata. ri is the dependent variable, and MKT, SMB, and HML are the independent variables. This command will save the coefficients as the variables as shown below:
Steps 1 and 2
While using asreg in Stata, the assumption underlying Fama and Macbeth regression is that you have already applied step 0. Now, under this method, steps 1 and 2 will be performed using one single command. Before running steps 1 and 2, we will drop two variables _R2 and _adjR2, using the drop command (otherwise, we will get an error).
drop _R2 _adjR2
After this, we will run the regression using the below command:
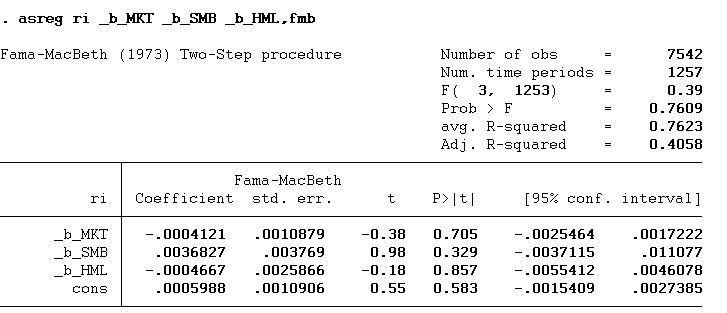
asreg ri _b_MKT _b_SMB _b_HML,fmb
Instead of using the variable, we will use the beta coefficients of our independent variables (MKT, SMB, and HML). fmb in the above command is an option that stands for Fama Macbeth regression. The fama macbeth regression t-statistic and coefficients as shown below and are precisely similar to the ones we got using the manual method:
Omitted Variable Error
Sometimes, people mistakenly use the actual variables (such as MKT, SMB, and HML) instead of their corresponding beta coefficients in regression analysis. This error occurs because MKT, SMB, and HML values are the same for every company in the dataset, hence a constant instead of a variable.
Using them as-is in a regression model is equivalent to using constants, and it doesn’t capture any variation or information that might be useful in explaining the variation in the dependent variable. The error is shown below:

Newey-West Consistent Standard Errors
We can also use the newey option with asreg command to correct the time series autocorrection error. The command is given below:
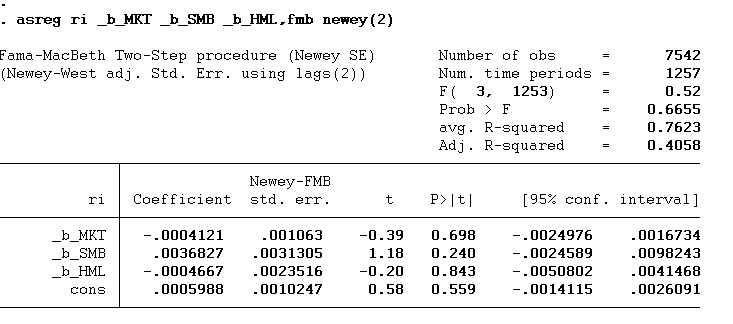
asreg ri _b_MKT _b_SMB _b_HML,fmb newey(2)
The remaining command will remain the same. Only the newey option will be added with the lag numbers within the parentheses. The number of lags in our case is 2.
XTFMB Command
XTFMB is another command to perform the Fama Macbeth Regression. To execute this command, we will first perform the step 0 using the below command:
statsby, by(symbol) saving(step0): regress ri MKT SMB HML
Now, we will merge the step0 file with the main file using the command below.
merge m:1 symbol using "step0.dta"
Once the beta coefficient is merged, we will perform the xtfmb command. One problem with this command is that it does not work with the variable having “_” in its name. So before executing this command, we will rename the variable _b_MKT _b_SMB _b_HML with MKT SMB HML using the commands below.
drop MKT SMB HML rename ( _b_MKT _b_SMB _b_HML) (MKT SMB HML)
Now, we will run the xtfmb command given below:
xtset symbol date xtfmb ri MKT SMB HML