
Select function is used in R to filter Columns, just like filter function is used to filter rows in data.
To know how the filter function works, select the working directory and once it has been set up, the tidyverse package needs to be installed, and we need to run tidyverse library to use the select function. Commands tidyverse package and library are as following command
Download Code and DataInstall.packages(tidyverse) library(tidyverse)
Next, import the data set that we are going to use for the select function in R. The data is imported from the following command
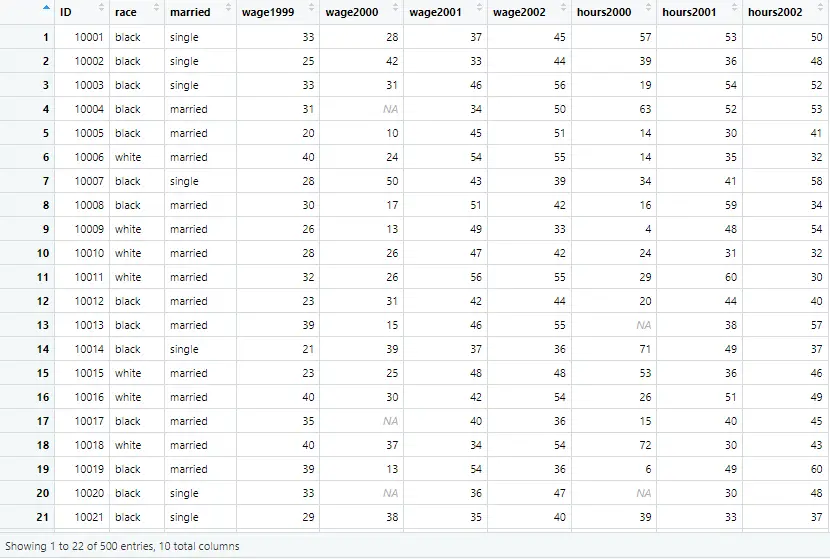
example_data <- read.csv("Example data.csv")The data has 500 observations of the 10 variables, named wage, race, married etc., as shown below.
Moving on to use the select command, we filter certain columns having the title of the columns present in the filtered data. To do so, we use the following command
filtered <- example_data %>% select(race,married, ID ) %>% head()
The filtered is the name of data given to the filtered data, and %>% is the pipe operator that is used to run multiple commands at a time. The head() function takes the first rows of the data set in the filtered data. The data that becomes filtered is shown as following
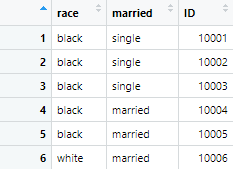
The order of variables is race, married and ID because we set the order of variables with the select function that should appear in filtered data.
Similarly, if the number of columns, instead of the name of variables is used in the above command, the same results will be generated. The command will be as following
order<- example_data %>% select(2,3,1) %>% head()
The number 2, 3, 1 shows the number of columns and their order, that we want in filtered data.
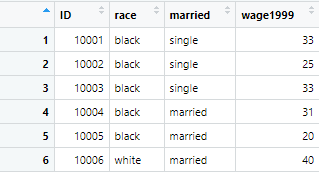
We can also filter columns using the range of columns. If we want to filter the columns from 1 to 4 in the data set, the following command will be used,
columnfilter<-example_data %>% select(1:4) %>% head()
This command filters the columns from 1 to 4 in the following way
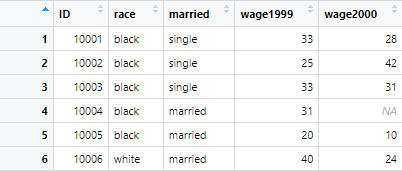
Similar, if we want to filter the columns using the range from names of columns, instead of the number of the column, as we did above, the following command will be used.
wage<- example_data %>% select(ID:wage2000) %>% head()
The data will be filtered from ID variable to wage2000 variable from the above command. The filtered data looks like following
Rename variable using select function
The variables can be renamed in the data too using select function in R. To rename the variables, the select function is used with the new name of the variable, and that should equal the old name in the command. The command for renaming the variable looks like following
example_data %>% select(employee_race = race, employee_id = ID ) %>% head()
In the above command, the name of the variable race should be replaced by employee_race and the ID should be replaced by employee_id.
Running the command will replace the variables with new names in the example_data set. However, an additional function named mutate() allows you to create new variables (columns) in a data set based on transformations applied to existing variables. It does not modify the original data set, but returns a new data set with the added columns. Thus, mutate() function is applied to the resulting data frame.
example_data %>% select(employee_race = race, married, employee_id = ID ) %>% mutate(race2 = employee_race) %>% head()
In the above command, married is not renamed because there is no new name assigned to it.
Excluding variables from the data set:
Variables or certain columns can be excluded from the data set using minus (-) or exclamation mark (!) in R. As both these signs indicate not to include the specified variables in the data, these columns would not be included in the filtered data.
For instance, if we don’t wish to include ID variable in the data set, we can use the minus option with the ID variable in the command
example_data %>% select(-ID) %>% head()
Or if we want to exclude ID variable using the exclamation mark, the following command will be used
example_data %>% select(!ID) %>% head()
If there are multiple variables, that need to be excluded from the data set, the exclamation or minus sign will be used with each of the variables in the following way
example_data %>% select(-ID,-race,-married) %>% head()
Combining Select with other functions:
There are multiple functions with which start function can work. For example, if we want to filter the data in a way that it includes the variables that start with a certain word, that’s where the the select function comes handy. In this data set, if we wish to filter variables starting with the word “wage”, the select function will be used in the following way
example_data %>% select(starts_with("wage")) %>% head()All the columns starting with the word wage are filtered, as shown in the image below
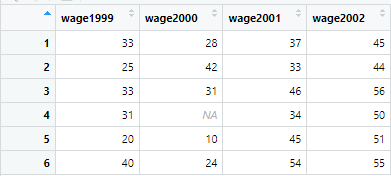
Similarly, there is an option of selecting the variables that end with a certain word. If we want to select the variables having 02 at the end of their name, select function will be used in the following way
endswith <-example_data %>% select(ends_with("02")) %>% head()The contain function is used with select function to filter variables that contain certain words of the requirement. If, for instance, we want to filter the example_data by filtering the variables containing the 20 word in it, the following command will be used
example_data %>% select(contains("20")) %>% head()