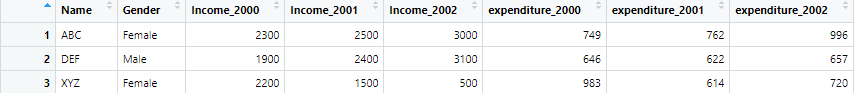Tidyverse package in R is one of the package that is used for reshaping the data. The reshaping of data is done by transforming data from long format to wide format and vice versa.
This article focuses on different issues that can arise from reshaping data in R. To go into detail of it, first set the working directory of session, where your data file is saved.
The next step is to install the tidyverse package and then load the library of tidyverse in R, using following commands
install.packages(tidyverse) library(tidyverse)
Remember that, if you have not installed the tidyverse package in R, above command will not run, thus giving an error.
Reshaping data from Wide to Long using Tidyverse in R
Once the package has been installed, the next step is to load data set. The data set we are using is example2.csv that is loaded in R by using following command
Download Code and Datawide_data_orignal <- read.csv("example2.csv", check.names=FALSE)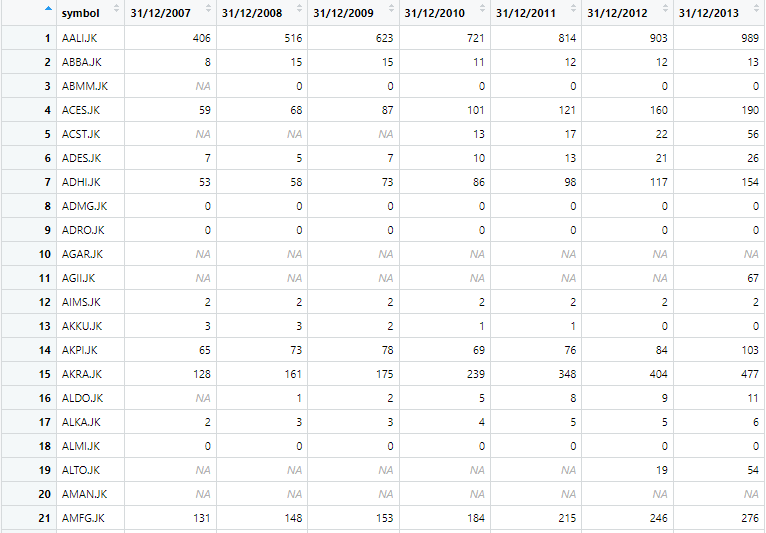
Now, if we convert data from wide to long format, it will be converted without any error. In long format, each row represents a unique observation and each variable has its own column. To convert the data from wide to long, use the following command.
long_data_piviotlonger <- pivot_longer(data = wide_data_orignal, cols = -symbol, names_to = "Year", values_to = "stock_price") %>% drop_na()
Here, long_data_pivotlonger is name given to data that is reshaped in R from wide format to long format. It requires several other parameters with it too.
First, we are required to provide the name of data set that needs to be converted, which is wide_data _original here. Next, we specify columns that we want to reshape. We wish to reshape all the columns present in data set, except the symbol column. To prevent symbol column from reshaping, we use minus(-) with symbol column. Minus sign works like exclamation mark, that is, it will exclude the column that is not required to be reshaped. Minus sign will instruct R to exclude that column while reshaping data. In this case, symbol is the column that we don’t want to be reshaped. So by adding minus sign with column “symbol” R will select all other columns except symbol column while reshaping data.
Additionally, we need to specify the names of the new column that will be generated from reshaping data from wide to long. As in wide format, the columns are years e.g. 2007, 2008 and so on, we name the new column “year”. Lastly, the name of the new column that will hold the values of variables will be specified. Since these values represent stock prices, a new column named “stock_price” is generated to store values.
“%>%”, also known as pipe operator, used in above command, instructs R to run the given command and the command that follows this command. As the next command after this is drop na(), it will drop the missing values present in data.
Reshaping data from Long to Wide using Tidyverse Package in R
While using tidyverse package in R, the reshaping of data from long to wide is done too. Next, we convert the data from long to wide. In wide format, each row represents a unique entity and each variable is spread across multiple columns. To convert the data set from long to wide, the following command will be used.
wide_data_piviotwider <- pivot_wider(data = long_data_piviotlonger, names_from = "Year", values_from = "stock_price")
Here the data set is named wide_data_pivotwider, and the column names will be taken from the observations of year variables, and the values of respective years will be taken from stock prices.
The data set will look as follows
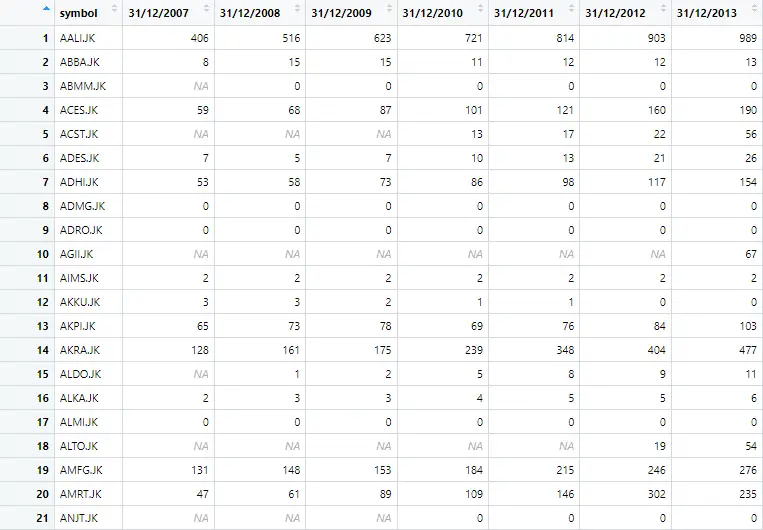
Multiple Unique Identifiers in a dataset
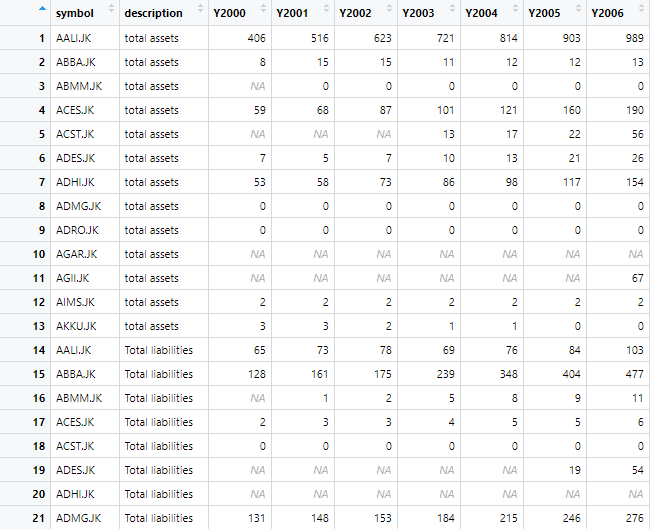
Till now, we worked with a data set that is identified by the single variable named “symbol”, but what if there are more than one unique identifiers. To deal with such kind of data set, let’s import a new data set using following command
wide_data_orignal <- read.csv("example3.csv")Now the data set has two identifiers; symbol and description, as shown in image below
Next, we transform or reshape the data set from wide to long. The command for reshaping data set is as following
long_data_piviotlonger <- pivot_longer(data = wide_data_orignal, cols = !c(symbol,description), names_to = "Year", values_to = "stock_price") %>% drop_na()
The explanation for the features of the above command are same as explained earlier, where long_data_pivotlonger is the name given to the data set, year is the names of the new column that will be generated from reshaping data from wide to long, values of the variables will be stored in stock prices column.
%>% is used to select and run the multiple commands at one time, i.e. the command that converts data set from wide to long and the command that drops missing values.
Additionally, we have an exclamation mark with two columns, instead of only symbol column. Now description and symbol columns don’t need to be reshaped, so exclamation or minus sign will be added before the names of these columns. R will select all the columns except these two for running the command.
Similarly, reshaping data from long to wide requires to run the following command, which is essentially the same command with same properties used earlier
wide_data_piviotwider <- pivot_wider(data = long_data_piviotlonger, names_from = "Year", values_from = "stock_price")
Multiple identifiers and multiple variables
We dealt with data sets having single identifier and multiple identifier. But we can come across different cases, where multiple identifiers and multiple variables are not required to be reshaped. For this purpose, we use another data set, saved by the name of example4.csv. To run that data set, use the following command
wide_data_orignal <- read.csv("example4.csv")Data set looks like following, once it is loaded
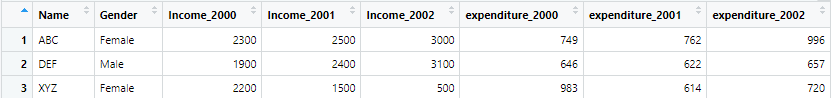
This data set has different variables for different identifiers. The identifiers are name and gender, while the variables are income, years and expenditures.
To reshape this data set from wide to long, the same command is used, except a few changes.
long_data_piviotlonger <- pivot_longer(data = wide_data_orignal, cols = !c(Name,Gender), names_to = "Variable", values_to = "Value")
The data set is named long_data_pivotlonger and now the columns excluded from the reshaping are name and gender. The exclamation mark or minus sign is used before these columns names to instruct R from not including these columns during reshaping. Rest of the command remains same. The reshaped data looks like following
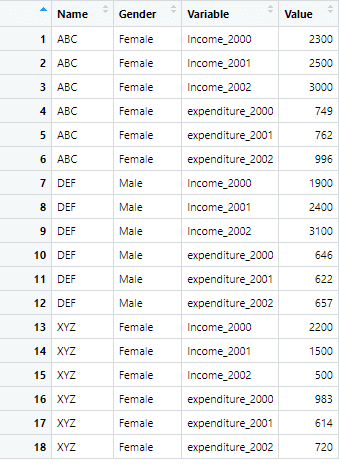
However, we want two variables in the above data set. The one variable should have the year information in it, and the other variable should contain the variables names i.e. expenditure and income in it. In other words, as visible in above image, the variable column has variables by the name of income_2000, income_2001, expenditure_2001, expenditure_2002 and so on. If we interpret this information, it is obvious that the next column named “values” contain value of income from 2000, income from 2001, expenditure from 2001 and 2002 and so on. However, we want years to have a separate column, and expenditure and income to have a common column.
To separate years from the variables, we use the names_sep function in R. This will separate the information in variables column and make two columns of year and variable instead.
The command is as following
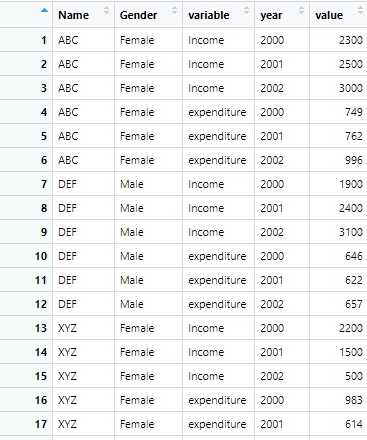
long_data_piviotlonger <- pivot_longer(data = wide_data_orignal, cols = !c(Name,Gender), names_to = c("variable","year"), names_sep = "_" )After the command is run, the data set looks as following, having separate columns for year and variables
Now, if we again want to convert data from long to wide, we use the similar command used earlier, except the names that were taken earlier from year, but now names would be taken from years and variables. The command is as following
wide_data_piviotwider <- pivot_wider(data = long_data_piviotlonger, names_from = c("variable","year"))Running this command converts data back to original data, as shown in image below