
Stata, a widely-used statistical software package, boasts a plethora of features that streamline data management and analysis. Among these features, clone variables stand out as a powerful tool that offers researchers greater flexibility and control over their datasets. In this article, we will delve into the concept replicating or cloning a variable.
The `generate` command in Stata is specifically designed to create new variables based on expressions involving existing variables or constants. While you can use it to create copies of an existing variable, it is not the most efficient or straightforward method for doing so. The reason is that you will lose the variable and value labels if you use generate command to replicate a variable.
Download Example FileUsing clonevar in Stata:
Creating a clone of a variable in Stata is a straightforward process. Researchers can utilize the `clonevar` command, followed by the original variable’s name and the desired name for the clone variable. For example:
“clonevar newvar = originalvar”
Once the clone variable is created, it exists as an independent copy of the original variable, carrying only the raw data. Consequently, any modifications or alterations made to the clone variable do not affect the original data.
Certainly! You can create clone variables while using `if`condition in Stata. The `if` condition allows you to conditionally perform operations on data based on specified criteria. Let’s consider an example where we have a dataset of students and their test scores, and we want to create a clone variable for test scores that meet a certain condition (e.g., scores above a certain threshold).
Suppose we have the following dataset:
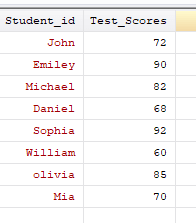
Now, let’s say we want to create a clone variable called `high_score` for test scores above 80. We can achieve this using the `if` condition as follows:
clonevar high_score = Test_Score if Test_Score > 80
After executing the above command, a new variable named `high_score` will be created in the dataset, containing the values of `test_score` only for those students who scored above 80. All other observations in `high_score` will be missing.