In R, we can merge different data frames for the data analysis purpose. There are two ways to merge data frame, either by using the merge() function in base R or by using tidyverse package, we will discuss both in this article . The merge() function merges the data based on a common variable or column, and can merge the data frames efficiently.
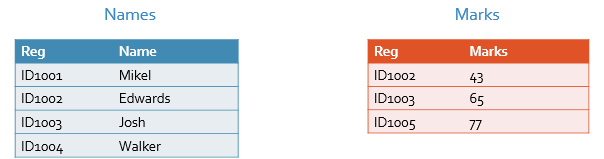
Let’s say we have the following data set, having two tables. The names table contains registration number and names of students, while the marks table contains registration numbers and marks of respective students. Let’s name “Names” table as table 1 and “Marks” table as table 2. We can see that the registration number is common in both the tables, and thus we can use registration number to combine these tables to merge both of these tables forming a complete data set, that contains registration numbers, names and marks of students.

We create the above data set given in the tables by using the following commands, where we would have registration number and names in table 1, and registration number and marks of students in the table 2.
Download Example Filenames <- data.frame(reg = c("ID1001","ID1002","ID1003","ID1004"), name = c("Mikel","Edwards","Josh","Walker")) marks <- data.frame(reg = c("ID1002","ID1003","ID1005"), marks = c(43,65,77))Once the commands have been executed, the table 1 and table2 are formed in R.
Now if we want to combine these tables using the merge() function, we can do that by the following command, which will combine the table 1 with the table 2, based on the common registration numbers.
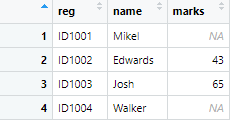
m_left <- merge(names,marks, by = reg", all.x = TRUE) m_left <- merge(names,marks, by = reg", all.y = TRUE)
In the above command, all.x = TRUE and argument specifies that we want to keep all observations from the names column, (x column) in table 1. Similarly, all.y = TRUE argument specifies that we want to keep all observations from the marks column, (y column) in table 2. The output from the above command will be as given below
Similarly, if you want to keep only observations having the same registration numbers in both tables, you can use the merge() function in the following way
m_inner <- merge(names,marks, by = "reg")
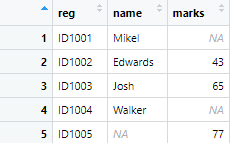
What if you want to keep all the observations from both tables? merge() function got you covered. It will merge both tables by keeping all the observations. The command will be as following
m_full <- merge(names,marks, by = "reg", all = TRUE)
The command gives the following output
All the possible options for merging two data frames can be done using the merge() function.
Merging data frames using Tidyverse package
There is an easy way to merge the data frames, by using the functions available in tidyverse package. We first load the tidyverse package by using the following command
library (tidyverse)
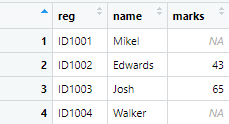
We want to merge data frames in such a way that, marks of students in table 2 are shown in front of their respective names in table 1. Given that registration numbers is a common column in both tables, we join the tables by this column. And as we want to add marks to the table 1 (left table or the table specified first in the left_join function), we use left_join() function in the following way
left <- left_join(names,marks,by = "reg")
Similarly, if we want to add names, in the table 2 where registration numbers and marks are already present, we can use the right_join function, which will add names of students in front of registration and marks in table 2 . The command used for this purpose will be following
right <- right_join(names,marks,by = "reg")
The output for the above command will be as shown below
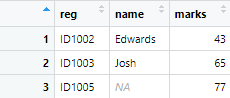
Notice that in left_join and right_join, there are 4 and 3 observations, respectively. This is because the both commands retain their original data set and merge the second data set into it.
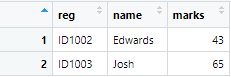
The third function, used for merging the data frames, is inner_join(). The inner_join() function retains only the observations present in the both tables. As in our original data set, there are only two observations that are common, the inner_join() function will only merge these two observations forming a new table. T
To merge these common observations, we use the following command
inner <- inner_join(names,marks,by = "reg")
The following output is generated from the above command, showing two observations from both tables merged.
The next function to merge data frames in R is full_join(). The full_join function retains all the observations in both tables, and combine them. If we want to merge both data frames using full_join, we use the following command
full <- full_join(names,marks,by = "reg")
Once the command has been executed, the result for command will contain all the observations in output.
Another function, although not useful for the merging data frames, is semi_join. The semi_join function doesn’t actually merge the data frames, but only retains the observations which are common in both tables. Like if we have two tables, as created at the start of article, it would only retain observations in table 1, if those observations are present in table 2. In this case, given that only 2 registration numbers are common in the both data frames, it would only retain those registration numbers and the names of students.
The command for the above operation will be following,
semi <- semi_join(names,marks,by = "reg")
We do have another function, that works quite opposite to the semi_join. This function is anti_join, and it would only retain the observations that are not common in both tables. So in the above tables, it would only retain the first and fourth observations not present in the second table. R seems fun now, right
The command for using the anti_join is following
anti <- anti_join(names,marks,by = "reg")
Merge different variable names
We can also change the column names while merging the data frames in R. To visualize this, let’s clear the previous data operations, and load the data set again by using the following commands
rm(list=ls()) names <- data.frame(reg = c("ID1001","ID1002","ID1003","ID1004"), name = c("Mikel","Edwards","Josh","Walker")) marks <- data.frame(ID = c("ID1002","ID1003","ID1005"), marks = c(43,65,77))Notice that in above data frames, the rest of data is same as before, except the ID column in table 2 , which replaced the “reg” column. Because we don’t have a common column to merge two data frames, the commands used above wouldn’t run. So we need to change the name of ID column to reg column as before. To change the ID column name to “reg”, while merging the data frame, we can use the command below
left <- left_join(names,marks,by = c("reg" = "ID"))This will change the ID name to registration and then merge the data on registration basis.
Merge data based on Multiple Variables
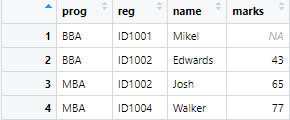
Now imagine that you have two data sets: one containing student information such as names, registration numbers, and their programs (like BBA or MBA), and another containing their exam marks. The problem is that students with the same registration number can be in different programs.
For instance, suppose we have a student named Edward in the BBA program and another named Josh in the MBA program, both with the same registration number. When merging, we want to ensure that Edward’s data is matched with his program (BBA) and Josh’s data with his program (MBA) without mixing them up.
To clear the previous data sets, and create data set explained above, we use the following commands
rm(list=ls()) names <- data.frame(prog = c("BBA","BBA","MBA","MBA"), reg = c("ID1001","ID1002","ID1002","ID1004"), name = c("Mikel","Edwards","Josh","Walker")) marks <- data.frame(programe = c("BBA","MBA","MBA"), ID = c("ID1002","ID1002","ID1004"), marks = c(43,65,77))Once the data frames are loaded, we merge these data frames, by using the following commands
left <- left_join(names,marks,by = c("reg" = "ID", "prog" = "programe"))The above command merges the data set in the following way