
Comparison of two data sets helps understand the characteristic features of different variables across the two data sets. We can compare the entire data sets as well as the variables in both data sets. These variables can be compared efficiently by using STATA. We can do that either by using the menu i.e., Data>Data utilities> Compare two data sets or through commands. To better understand the procedure with commands, we will proceed with an example. STATA has an inbuilt data set and to use that data set and to import it we have to run the command:
Download Example Filesysuse auto, clear
This command uploads the data set to STATA. Suppose that we are making some changes to the above data sets which can be done through commands:
drop price replace mpg=1 in 6/7 replace mpg=. in 6/7 tostring weight, replace
Related Article: How to Convert String variable into numeric in Stata
By running these commands, we made slight changes to the original data set: We dropped a variable “price”, replaced the values of “mpg” from 1 to 5 to ‘1’, 6 and 7 to missing values and changed the storage type of “weight” from ‘int’ to ‘str4’. Finally, we saved this data set to “changed data.dta” by using the below command:
save "changed data.dta", replace
Now, we will open another data set which we will use to compare to “changed data.dta”. For doing so we have to load new data set to the STATA interface by using the below command.
sysuse auto, clear
Make sure that this data set remains unchanged. Now we want to compare this data set to “changed data.dta”. This comparison can be done by using “cf” command. The “cf” command compares variables and values of variables but if the labels of the variables are not same then this command won’t mention it.
Suppose we want to compare few variables such as “price”, “mpg” and “weight”. In such case we have to rely on following command
cf price mpg weight using "changed data.dta"

The result for this command shows that variable “price” does not exist in “changed data.dta” and has reported 7 mismatches for “mpg” variable.
What if we want to compare all the variables across the two data sets than we have we have added “_all” or “*” commands alongside “cf” command as below.
cf _all using "changed data.dta"
This command reveals the below results which are the mismatches across two data sets. These results show that “price” does not exist in “changed data.dta”, 7 mismatches are observed in “mpg” while the storage type for “weight” is integer in “changed data.dta” while it is string in Master data set.

The above results can also be obtained through the command:
cf * using "changed data.dta"
Since this command does not show the remarks for all other variables. What if we wanted to see remarks for all the variables. For doing so, we have to run the following code with addition of “all” option.
cf _all using "changed data.dta"
This command will give us below results which are detailed remarks of all the variables across the two data sets. This command does take all the variables in Master file and compares them to using file. Any change in master file will give us changed results.

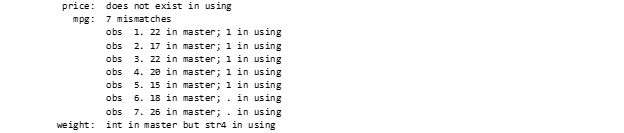
What if we are interested to get the details about the mismatched results. Such results could be obtained through “verbose” option. This option provides the characteristic features of the mismatched variables. If the mismatches are fewer than verbose option is useful however with larger number of mismatches the verbose function won’t be useful.
Related Article: Use of Compare command in Stata to compare variables
cf _all using "changed data.dta", verbose
The below table is the result of the verbose command.
There are other additional commands such as “cf2”, “cf3”,” cfby” and “cfout” which are also useful to compare data sets and each of them has its own uniqueness.