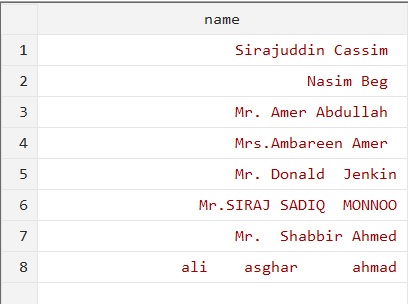
In this article, we’ll explain how to clean, extract, and modify string variables in a variety of ways. In both programming and data analysis, string variables play a crucial role since they often contain textual information that must be manipulated and processed. Data consistency and accuracy can be improved by “cleaning” string variables by deleting unnecessary characters like spaces, punctuation, and other symbols. To extract anything from a string means to separate it into its component parts using some kind of criterion or pattern. The dataset we will be using in this article of one variable that is string variable “names” as shown below figure:
We will generate a new variable that will be the duplicate of the variable “name”. All the commands will be run on one variable while keeping the other variable the same. This will allow you to keep the original data while monitoring the changes. The below command will be used for that purpose:
gen name2 = name
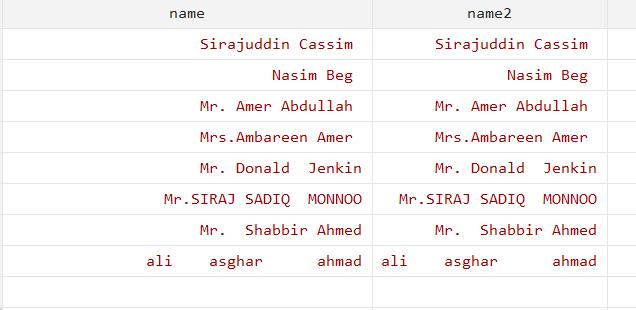
In this article, we will change the variable “name” while keeping the variable “name2” as original observations.
Trim Function:
It’s common for problems to arise when downloading data from specific websites, such as the downloaded data may have trailing or leading space, and even multiple spaces that are often unnecessary and should be removed to guarantee clear and useable data. When a string ends with a blank space, it is said to have trailing blank spaces. Instead, the data begins with a blank space known as a leading blank space. To remove the space, we use the trim function.
replace name=rtrim(name)
The names with space at the end will be removed after running the below command.
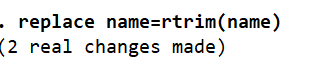

Two observations in our dataset have been modified by eliminating trailing spaces. To remove the leading spaces the following command can be use:
replace name=ltrim(name)

No observation in our dataset has leading space, so no change has been made. We have an alternative command that also remove any leading or trailing space in our dataset.
replace name=trim(name)
Spaces at the beginning and end of a value are eliminated so that only the content is left by removing all unnecessary spaces. Another command that can be used is also given below:
replace name=strtrim(name)
This command is meant to tidy up the “name” variable by removing trailing or leading spaces. The command that uses to remove the consecutive internal space within a specific observation is given below:
replace name=itrim(name)
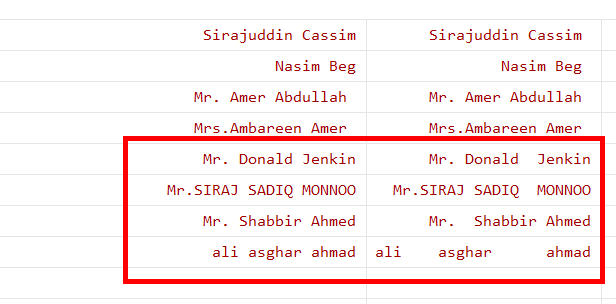
You will notice that internal space within the last four observations has been removed. It is possible to encounter unicode characters that are neither numerals nor strings when copying information from PDFs or websites. These symbols can be represented graphically as emojis, special symbols, or other forms. So, to overcome that, below given commands can be used:
This command will remove any spaces or other whitespace characters from the start of the string values.
replace name=ustrltrim(name)
This command will remove any spaces or other characters from the end of the string values.
replace name=ustrrtrim(name)
This command will remove any spaces or other whitespace characters from the end or start of the string values.
replace name=ustrtrim(name)
In this command, “u” represents the Unicode.
Extracting Specific Sub-Text
To extract the specific characters from the variable “name”, we can use the substr function. There are three parameters that we need to provide to the substr i.e. the name of the variable, the position of character from where to start extraction process and the number of characters to extract.
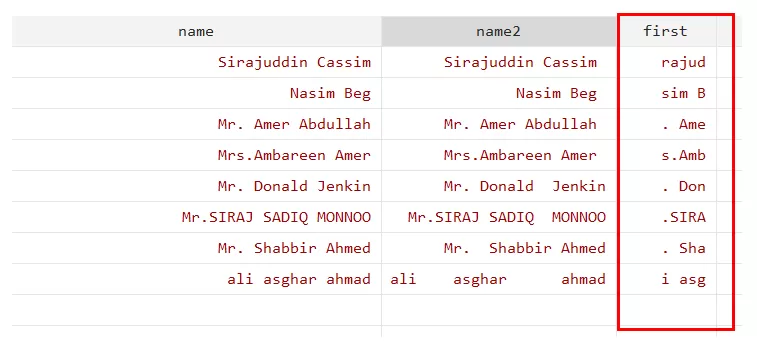
generate first=substr(name,3,5)
The generate is a command that will generate a new variable named “first”. This substr() function will specify the substring extraction operation. This function will pull out a substring beginning at the third character position and continuing until the fifth character position of each string value.
To extract the word from the name, word function can be use as specified below:
generate get_word=word(name,1)
The generate is a command that will generate a new variable named “get_word”. The word() function will specify the variable in which we are interested, for example in our case we are interested in “name” and the position of the word we want to extract.
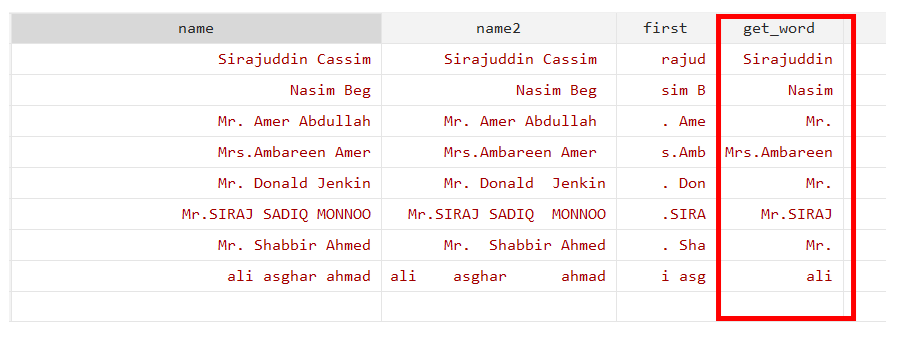
The command will extract the first word of the name. Note: The Stata assumes that anything separate space is a word.
String Length
If we want to count the number of characters of a variable then, strlen function can be use as specify below:
generate length=strlen(name)
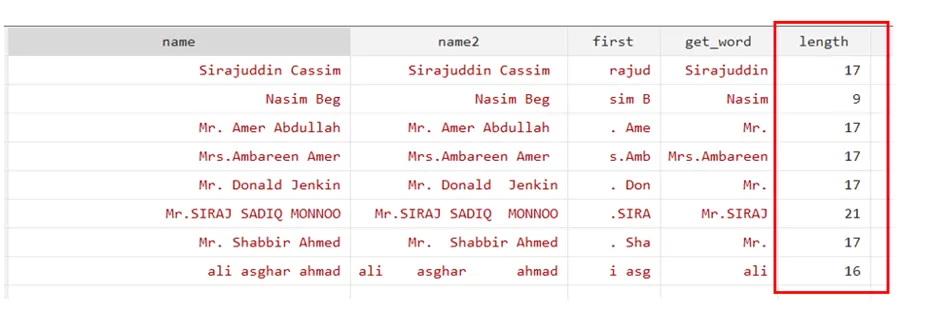
generate command will generate the variable(length). strlen function will count the number of characters in the name. For example, it says that Sirajuddin Cassim has 17 characters.
To count how many words are there in a name, the below command will be used:
generate word_count = wordcount(name)
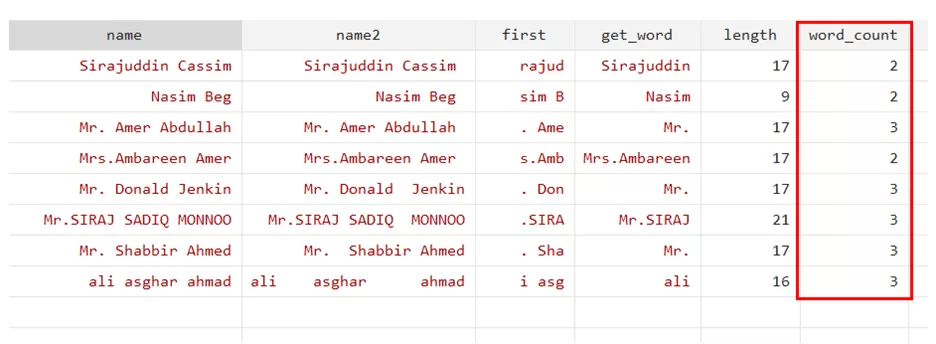
Its say that Sirajuddin cassim has 2 words.
Remove or Change part of String
We can also remove or change some parts of the string variable (name) using the function subinstr. Let’s explain it with the below command:
generate name11=subinstr(name,"ahmad","A.",.)
The parentheses of the subinstr include four arguments. The first argument is the name of the variable we are looking at. Second, the string ahmad that we want to replace. Third, the string (A.) with which we want to replace with Ahmed. Lastly, a “.” to change the Ahmad wherever it is occurring.
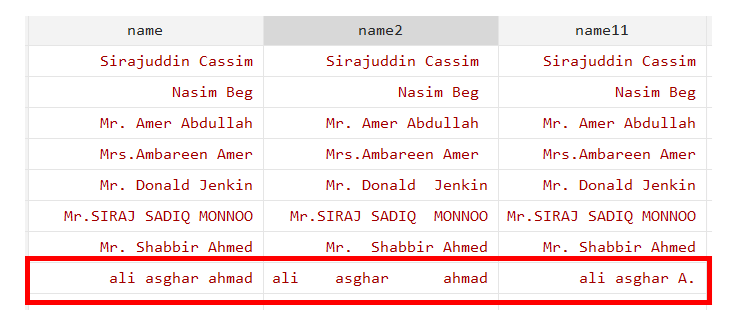
The ahmad has been replaced with an A. Similarly, if want to make change in first occurrence then instead of dot we can use 1. The “a” in all the first occurrence will be replaced with the “aaaa”.
generate name12=subinstr(name,"a","aaaa",1)
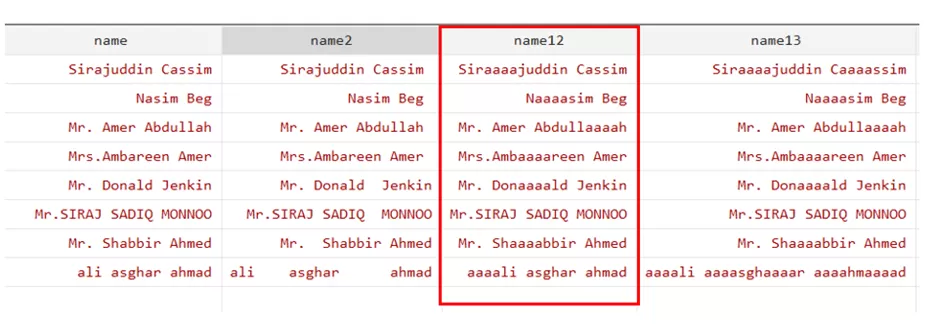
Note: only small letter “a” will be change. Also if we want to change all the “a” “a” into “aaaa” then replace 1 with dot.
generate name13=subinstr(name,"a","aaaa",.)

Position of Specific Character
We can also find the position of the specific character or word in the individual’s name using the below command.
generate position=strpos(name,"Mr.")
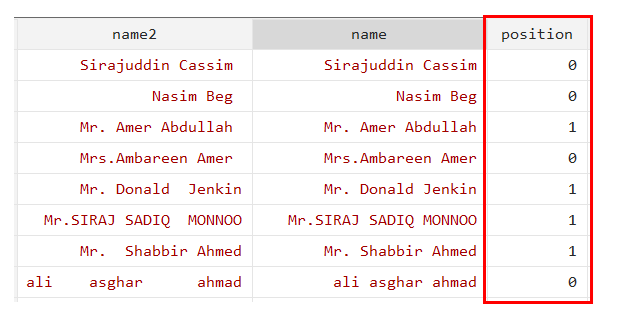
A value of 1 is assigned to the variable “position” if the name begins with “Mr,” and a value of 0 otherwise.
Change the Text Case
All the string values (names) can also be converted into the upper case using the command below in which strupper function has been used.
gen upper=strupper(name)
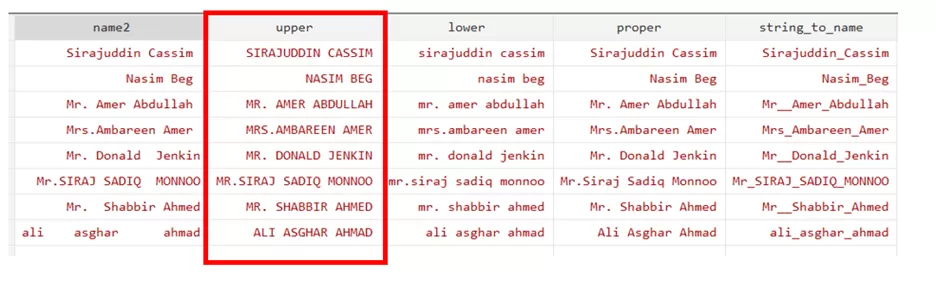
To change the string values (names) into lowercase, use the below command in which strlower function has been used.
gen lower=strlower(name)
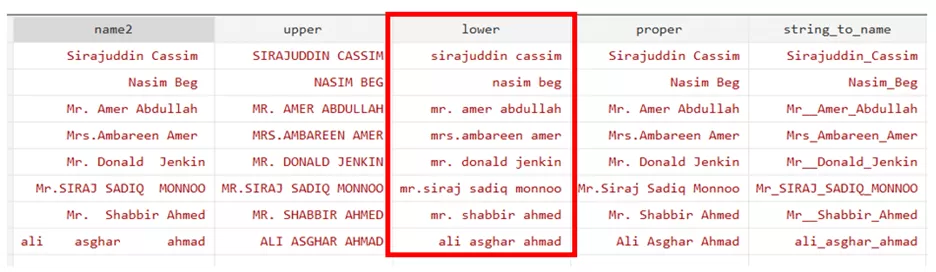
To change the string values (names) into the proper case, use the below command in which the strproper function has been used. A proper case is one in which the word’s first letter will be capitalized.
gen proper=strproper(name)
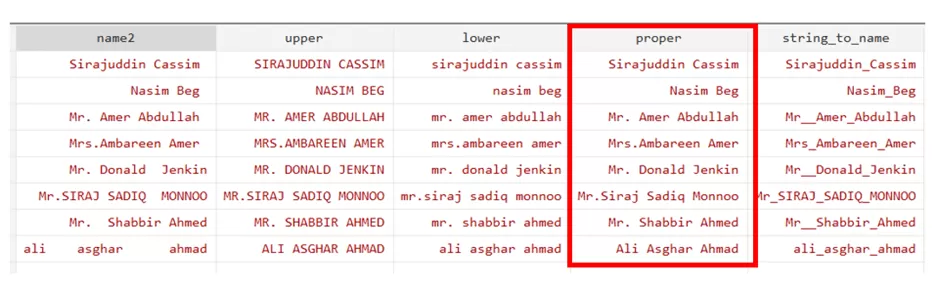
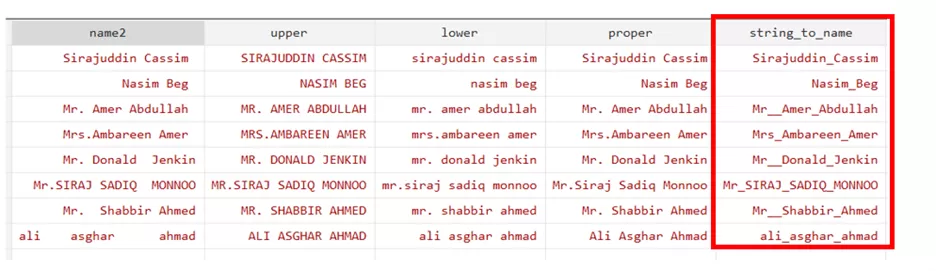
We can also replace the space within the names with the _ by using the below command. It basically change the string into the name.
gen string_to_name = strtoname(name)
Match Words
The string value can also be matched using strmatch function. It checks whether there is a specific name or not. It gives 1 if a match is found and 0 otherwise.
gen match1 = strmatch(name, "Mr.")
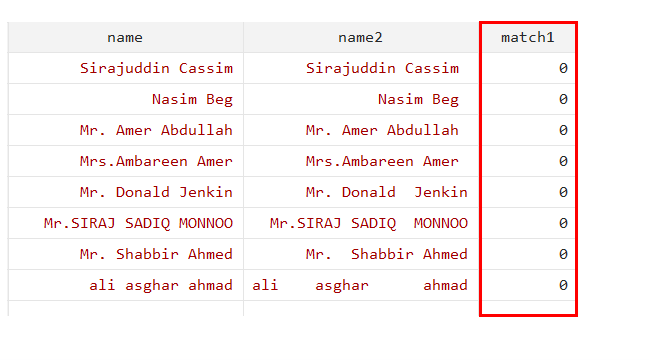
As there was no Mr. alone. There are names after Mr. therefore, we will use the below command that includes *.
gen match2 = strmatch(name, "Mr*")
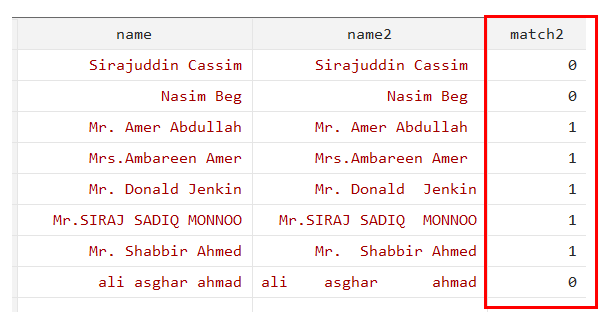
Value 1 was assigned to all string values (names) that began with “Mr.”
To split the name into different variables, use the below command.
Splitting
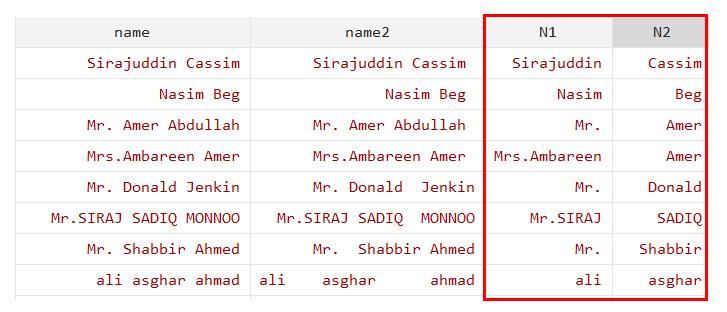
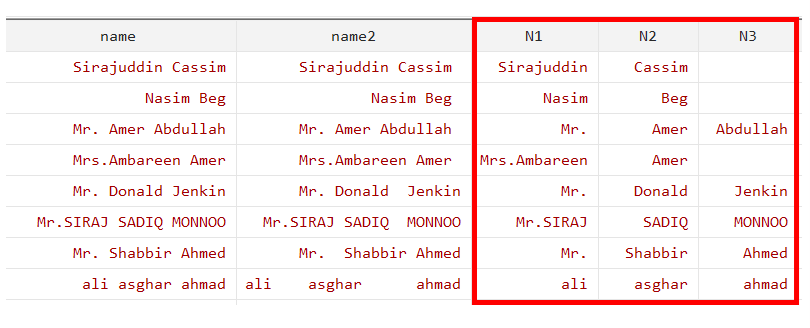
split name,generate(N)
split is the command. “name” is the variables and will generate variables (N1, N2, and N3).
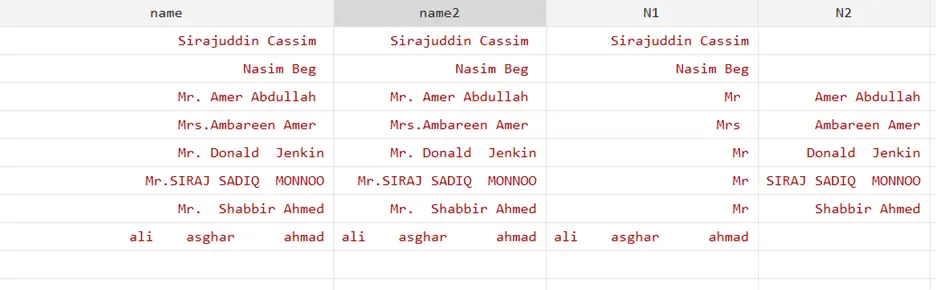
To separate the name after a specific character such as “.” Then it that case we use parse and write argument within the parentheses as shown in below command:
split name,generate(N) parse(.)
We can also limit the split by assigning a limit like 2 in our case, as shown in the below command: