
We are going to explore the topic of unique identifiers for panel data. While working with panel data, it is absolutely essential to correctly identify variables that uniquely distinguishes between each data point. We are going to understand the particular process of identifying variables. For that purpose, let us begin by importing the NLS work data from source. The command for importing the data would be
webuse nlswork
The command will show you the following data
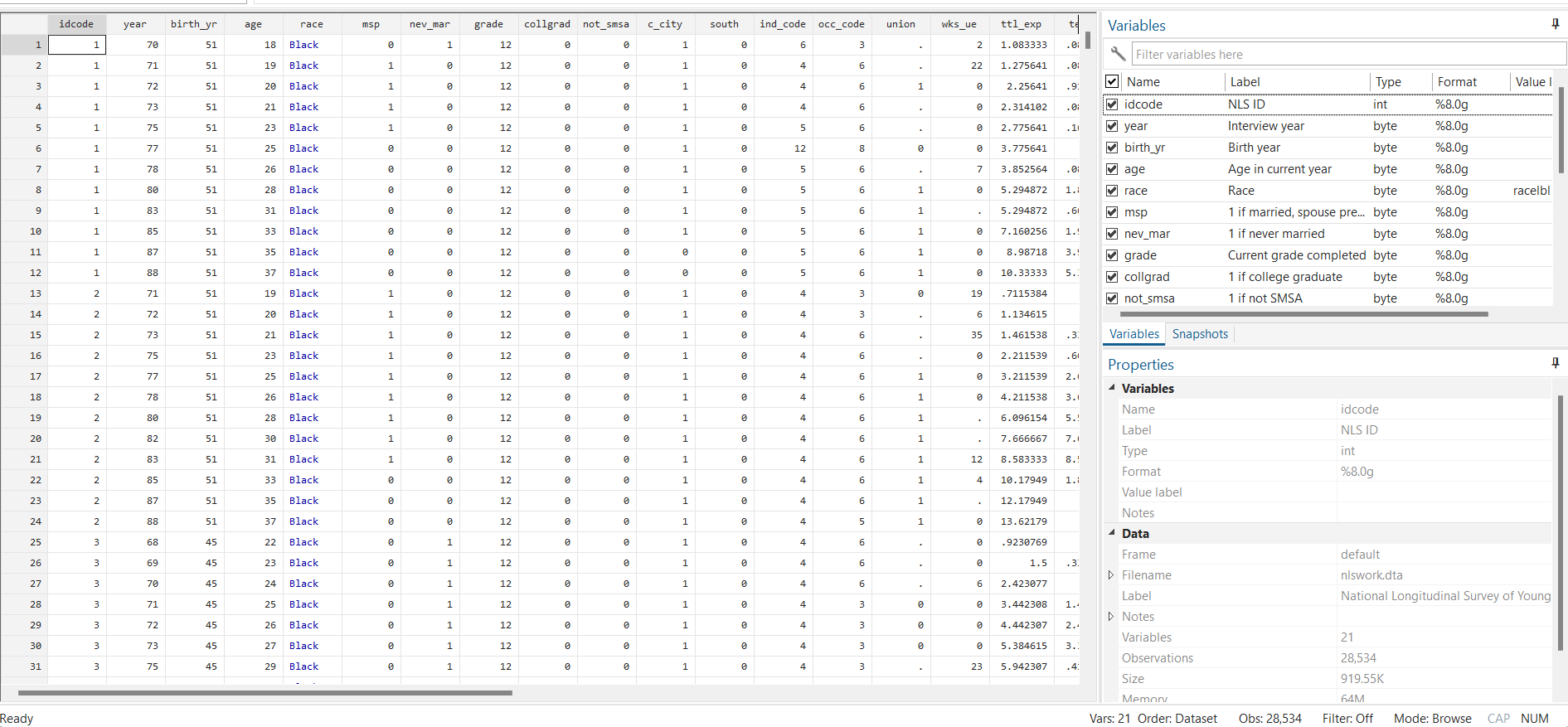
The data set we have in hand is panel data, which means it encompasses data across different individuals, identified by an ID. To explain, individual one, individual two, and so forth, each has corresponding data for various years. This data also has other attributes relating to every individual, such as birth age, race, number of hours they have worked and their log wage along with other logarithmic values.
It provides extensive data for each individual however, our focus lies in identifying the unique identifiers for observations. First we need to inform Stata that the data we have at hand is panel data. The command xtset along with the crossectional and time variable can be used to inform Stata that the data under consideration is a panel data.
Now to use xtset, we need a method to pinpoint variables that can truly distinguish data points. For this purpose we use isid command.
To determine if ‘Idcode’ serves as a unique identifier, we employ the
isid idcode
command. This command checks if a variable, in this case, ‘idcode,’ uniquely identifies the data. If it doesn’t, an error will be displayed. By running this command, you would see an ‘error’ or the following text pop up

Similarly, we assess the ‘year’ variable’s uniqueness. To do that, the command
isid year
would be used in a similar fashion. You will see the following text pop up

Both of these commands helped us to understand that unfortunately, neither ‘idcode’ nor ‘year’ exclusively identify observations.
Considering the nature of panel data, a combination of ‘idcode’ and ‘year’ is generally necessary. The command
isid idcode year
would ensure a successful turnup. It would not result in any error and “no news is good news as long as the isid command is concerned”. This would mean that the idcode and year uniquely identifies the data. This combination ensures the uniqueness of data points. Successfully passing the ‘isid’ command for this combination validates that it is indeed a unique identifier. As a result, we can utilize the following command
xtset idcode year
to specify the panel structure. You would be able to see something like this,

Duplicate Observations in Panel Data
It’s worth noting that issues can arise due to data duplication, as demonstrated by two identical observations. For the sake of example, let us suppose we have two exactly similar observations, as such

Attempting to use the command ‘xtset’ with duplicated time values, as given below,
xtset idcode year
prompts an error (“repeated time values within panel” as shown below
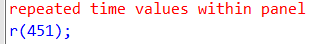
Similarly, the ‘isid’ command fails to address duplication concerns. Your command
isid idcode year
would also show an error like this,

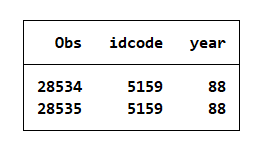
To resolve this, a command ‘duplicates list’ along with the unique identifier variables, as shown below,
duplicates list idcode year
can reveal instances of repeated values. It would rightly show you the duplicated observations as such
while ‘duplicates drop ID code’ with the ‘force’ option can remove duplicates. The command would look something like this
duplicates drop idcode year,force
By running this command, you would drop the repeated observation;

When encountering duplicates, it’s wise to investigate the cause, potentially stemming from data import errors. Scrutinizing the data may uncover discrepancies. Hence, before dropping duplicates, consider investigating their origin.
It is important to elucidate the significance of unique identifiers for panel data. Proper identification ensures accurate data analysis. We’ve learned to determine unique identifiers using the ‘isid’ command, comprehend the necessity of combined identifiers for panel data, and address duplication issues. By mastering these concepts, you’ll be well-equipped to work effectively with panel data in Stata. Happy learning!