
This article is related to identification and treatment of missing values in Stata. Sometimes data have missing values that can affect the statistical analysis and validity of the data. There could be many possible reasons for existence of missing values in data. These reasons can include non-response from interviewee’s, missing data entries or/and data loss during collection.
Identification of missing value
To identify missing values in data, first import the following data set in Stata.
Once the data has been imported, we can use the summarize command to identify whether missing values exist in data or not.
summarize
The following summary statistics is shown in Stata. Under the observations’ column, we can see that observations are same for all other variables except the hours variable that has fewer observations. This clarifies that 4 values are missing from that variable. Now if you run any kind of statistical test, be it regression analysis or any other tests, these missing values will not be included in it.
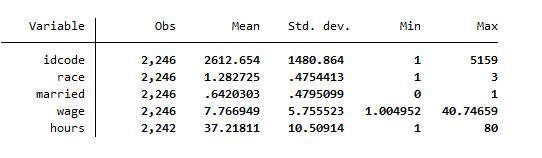
After the summarize command has been used, we know that hours variable has missing values. To find the exam number of missing values and other summary statistics of the variable, we can use following command
misstable summarize
This command will generate a table, having the number of missing values of the variable, total observations and maximum and minimum values as shown below.
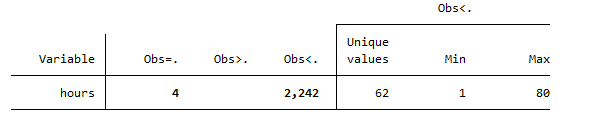
Another way to find the missing values in Stata is to use the mdesc function, which will define whether each variable has missing values or not. To run this function, we first install the mdesc function by using following command
ssc install mdesc
Once this function is installed, we can run the following command to check whether the missing values are present or not in the variables.
mdesc
The following table is generated, which shows that 4 missing values are present in the hours variable.
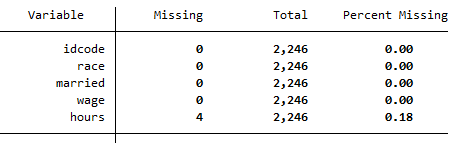
Missing values treatment in Stata
Now the missing values have been identified, we can see how they affect the statistical analysis of data. Let’s run a regression analysis that include hours, having missing values, as independent variable.
regress idcode married hours
The following regression results are generated that shows total observations in data are 2,242 instead of 2,246 observations that are present in idcode and marriage variables. Thus, it shows that regression results are biased and flawed due to missing values.
After the identification of missing values, the next step is to treat the missing values to correct the data. There are different methods that Stata use to treat missing values. One way to treat missing values is to replace the missing values by the mean of that variable. For instance, in this case we summarize the variable hours, that has four missing values, to find its summary statistics using the following command
summarize hour
The following summary statistics is generated that shows the number of observations and mean etc. of the variable.
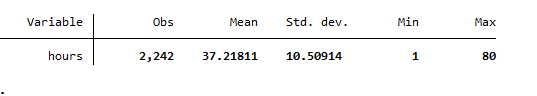
To treat the missing values, we can replace the missing values in the variable by its mean. To do so, the following command will be used
replace hours= 37.21811 if missing( hours)
Now the changes have been made in Stata, where missing values in the hours variable are replaced by its mean value.
Similarly, we can generate a new variable for hours that doesn’t have missing values, by using the mean values of the hours variable. The newly generated variable thus will contain only the mean values of the hours variable. This way you can retain the original hours variable and use the new variable that doesn’t contain any missing value. To do so, use the following command
egen hours_filled = mean( hours)
The new variable that we generated is hours_filled and contains mean value of hours variable.
Another method is to drop the missing observations from the variable if missing values are present. First, we clear the previous data from the stata using the following command
clear
Now again import the data from the file provided at the start of the article. Once the data has been imported, we can drop the missing values from the data as a treatment to the missing values. To drop the missing values, use the following command
drop if hours >= .
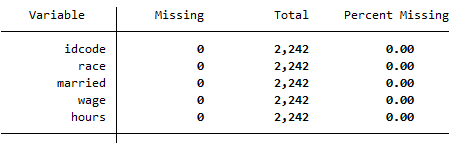
What this command does is it drops missing values that are present in the form of “.” in the Stata. Once the missing values have been dropped, we again run the mdesc command. The following result will be generated which shows no missing values are present in data
mdesc
Treatment of missing values using Interpolation
The interpolation method is the most common and famous way to treat the missing values in Stata. There are many methods one can interpolate the missing values in Stata. However, this depends on the type of their data set, nature of data set and pattern of missing values.
We will continue with interpolating of data set using ipolate method, which should be used when variables are continuous. Ipolate method is used for linear interpolation of missing values. It estimates the missing values of variable, based on linear relationship between two variables. What the ipolate command in Stata essentially does, it creates a linear interpolation of the one variable based on the other variable for missing values of the first variable. This means that when hourshas missing values, ipolate estimates those missing values based on the known values of hoursand their corresponding values in another variable, for instance ID code here.
To use ipolate for the missing values in hours, we use the following command
ipolate hours idcode , gen (hours_interpolate) epolate
This command generates missing values in Stata for the hour variable, using linear relationship between hours and ID code to generate new values. The newly generated variable, named hours_interpolate has no missing values.
very useful document