
Whenever you are working with more than one dataset, it is highly likely that you will need to combine them together to perform any analysis. In Stata, this is referred to as merging. There are different types of merges depending on the situation. Each type of merge is explained in its relevant sections. The topic of combining datasets is covered in quite a detail in Chapter 7 of Data Management Using Stata by Michael N. Mitchell.
Download Example FileMany-to-one Merge
Let us assume that we have several files on various firms. One file contains the leverage data for various firms in different years (i.e. each file has a panel dataset). We would like to add more variables to this dataset to be able to perform some meaningful analysis. For this, we have another dataset that has yearly data on inflation. We would like the inflation variable to be present in the leverage data as well.
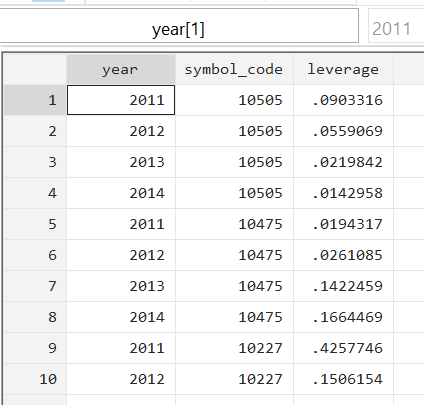
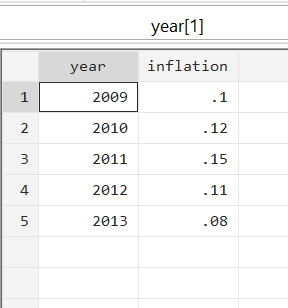
So, with the inflation variable taken from the second dataset, every observation for the year 2009 in the first dataset should show 0.1, for 2010, 0.12, and so on.
Remember that the append command is used to add new observations from one dataset to another. Here, we would like to add more variables and relevant data corresponding to the appropriate year and company. In simple terms if you wish to add more rows to a data then you will use append command but if you want to add more columns then merge command is the way to go.
There are a few things that need to be kept in mind when merging datasets.
The dataset that is currently loaded in Stata’s memory is referred to as the master dataset. The data that we wish to merge with the master dataset is called the using dataset. In our case, the leverage data is the master dataset, while the inflation data is the using dataset.
Secondly, both files may have different structures when it comes to certain variables. In the leverage dataset, the year variable sees its values being repeated several times for each firm. For example, using the command tab year, we observe that 2011 is repeated 388 times – each time for a different firm. Other years are also repeated in a similar manner. However, in the using file, since there is only one value for inflation for each year, we see 2009, 2010 etc. appear only once. This means we can say that ‘many’ observations in the master dataset can correspond to ‘one’ observation in the using data set. 388 observations for the year 2011 in the leverage dataset will correspond to one observation for inflation (0.15) in the inflation dataset. In short, the type of merge that the two files require is called a ‘many-to-one’ merge.
In order to merge two datasets, we need a common variable (or a set of variables) called a ‘key’ variable present in both the master and using file. In this case, it is year.
We can merge the data using the menu option provided in the following sequence:
Data > Combine datasets > Merge two datasets
Related Article: How to Combine Multiple CSV/Excel Files in Stata
In the dialogue box that opens, fill out the fields in the ‘Main’ and ‘Options’ tab as required:
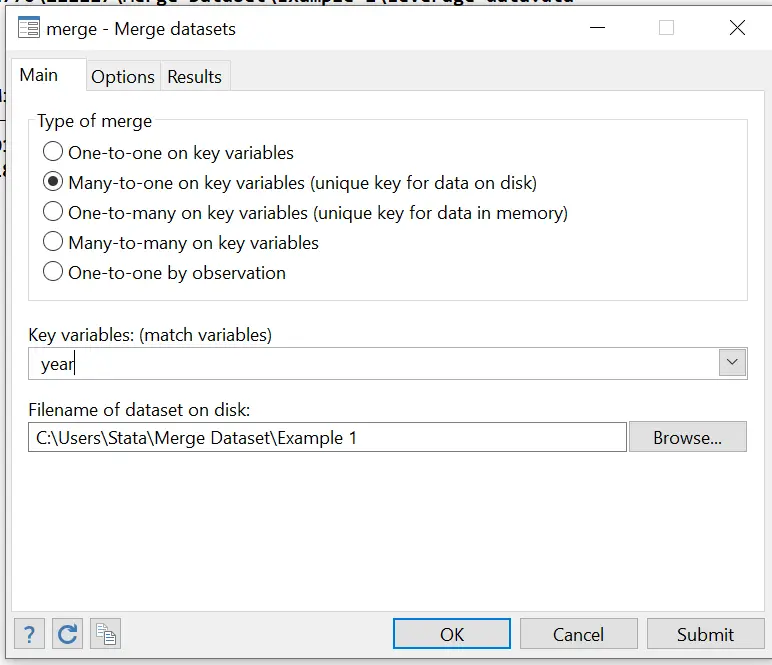
Press OK to merge.
The inflation variable will now have merged with the master dataset, showing the appropriate inflation rate for the corresponding year. A variable called ‘_merge’ will also be automatically generated to indicate how each observation merged between the two datasets.
Reading Stata Results
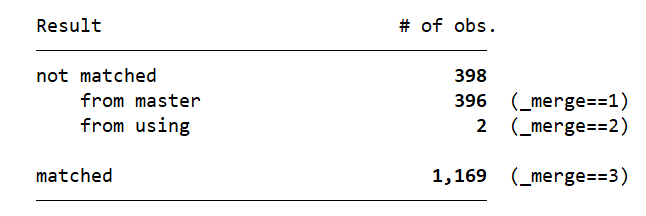
The last result in this output table shows us that 1,169 observations matched from the master data with the using data. For these observations, the _merge variable equals 3.
398 observations did not match: 396 from the master data file did not match with any data in the using dataset (i.e. they were present in master file but not in the using file), while 2 observations from the using dataset did not match with any observation in the master dataset. The former i.e., observations available in the master dataset but not the using dataset, are indicated with a ‘master only (1)’ in the _merge variable. For example, in the leverage data (the master dataset), there are some observations for the year 2014, but no inflation data for the year is found in the using dataset on inflation. Similarly, for the latter, the _merge variable shows ‘using only (2)’. In this case, the using dataset on inflation had inflation values for the years 2009 and 2010, but no observation for these years existed in the master dataset.
If you only wish to keep those observations that were matched from both files, the following command can be executed:
keep if _merge==3
This will drop all the 398 observations that did not match.
Many-to-many Merge: Merging Two Panel Datasets
Let’s suppose that alongside the leverage dataset, we now have a dataset on ROA (Return on Assets) for various years for each firm, and the two need to be merged together. The type of merge, and the key variable will now vary in this case. In both the master and the using file, each observation is unique to one particular firm in one particular year i.e., the key variable in both files is a combination of the firm (identified by the ‘symbol_code’ variable) and year.

This now means that one observation in the master file can be matched with only one observation in the using file. The merge type in this case will be called ‘one-to-one’ merge which will need to be specified in the dialogue box. Similarly, the key variables will also need to be added; this time two of them (symbol_code and year).
You can also try changing the name of the new variable that is created after each merge from the Options tab. By default, it is called _merge. You can alter this by typing in a name of your choice, or prevent it from being generated by checking the first option below it i.e., “Do not generate _merge variable”.
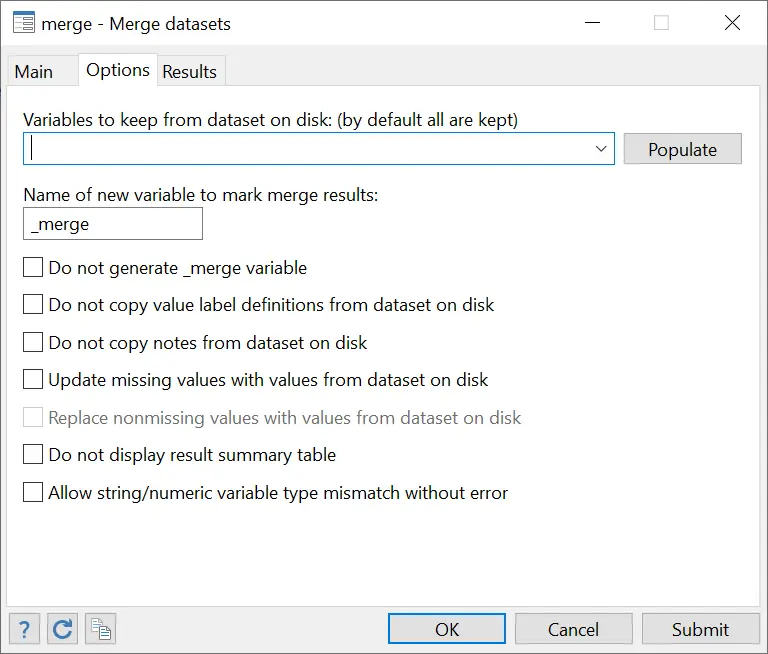
Similarly, you can further tailor the results that you want displayed from the ‘Results’ tab as well. For example, previously, we manually kept the observations that had a match in both the master and using file and deleted the rest. You can apply this setting beforehand by selecting the ‘Record appeared in both’ option under the ‘Results to keep’ section.
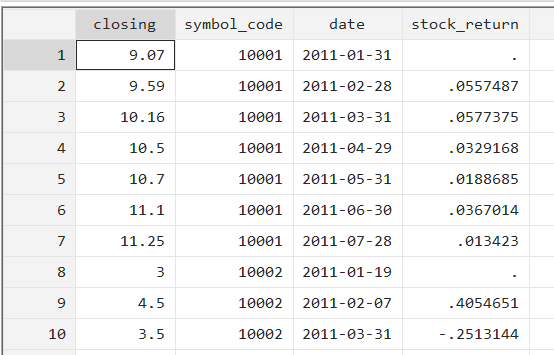
In our final example, let’s merge two datasets, one of which is monthly data on stock returns, and the other one is the same annual balance sheet data on ROA and leverage which we have used previously. The images below show a snippet of the monthly data on stock return and the yearly balance sheet data.

How then do we go about merging this monthly data with yearly data when no apparent key variable is common to both datasets? For that, we will first generate the year variable in our monthly data using the existing ‘date’ variable.
gen year = year(date)
This will now allow us to use the ‘year’ variable in both datasets as the key variable.
Following the same menu options as before, we now need to choose the type of our merge. Remember that we have 12 observations for each firm in a particular year in the monthly data (the master file), and one observation for each firm in a particular year in the using file. Our merge type will therefore be many-to-one. The key identifier variable will be both symbol_code and year. The merge will then be done in the same manner described above.
One-to-many Merge
Let’s do the last example the other way round by treating the yearly balance sheet data as our master file, and the monthly stock return data as the using file. We will save the monthly data with the ‘year’ variable in the same manner that we generated it before.
Open the yearly balance sheet data and follow the menu steps to merge two files:
Data > Combine datasets > Merge two datasets
This time, our merge type will be different. Because our master file has yearly data i.e. each year appears only once for one firm, one observation in this dataset will correspond to many observations in the using dataset. This is because, as mentioned before, the using dataset has 12 observations for each firm in each year. The year and symbol_code will once again be our key variables.
Many-to-many Merge
There are also instances where many observations in the master dataset can correspond to many observations in the using dataset. This is called a many-to-many merge. It is not always recommended to perform this merge as it can create some discrepancies when matching observations. Read Stata’s (interesting) documentation on this type of merge if you are curious about the dynamics of m:m merges!
One-to-one by observation
You will notice the last option in the list of the type of merges as ‘One-to-one by observation’.
This will just merge two datasets in a sequential manner. The first observation in the master dataset will be merged with the first observation from the using dataset. Similarly, the second observations in both datasets will be matched together, and so on. Naturally, there won’t be any need to specify a key variable in this case, since the merge is just being done in a sequential manner without trying to use any variables to match the two datasets. Therefore, the field for specifying the key variable will also be disabled.