
This article will discuss how to duplicate observations can be deleted or dropped using Stata. The duplicate observation or values are the identical observation that is repeated two or more two times in a variable. These duplicate observations or values sometimes create an issue, especially when using a panel dataset.
The data used in this article is panel data. Panel data can be explained as data that is both cross-sections as well a time series. Another name of the panel data is longitudinal data. This dataset has three variables named years (timevar), symbol_code (panelvar), and leverage. The data is of different firms, which are represented through a specific code (symbol_code). Along with it, the leverage value of each firm is provided for two years.
Before analyzing Stata on the panel dataset, it is a must to tell Stata that the data we are using is the panel. Therefore, to tell Stata about the panel data, the below xtset command will be used.
Download Example Filextset panelvar timevar xtset symbol_code year
After running the command, an error will appear, as seen below image.

This error indicates that the dataset used includes duplicate values.
Reporting duplicate values.
First, it is a must to report the duplicate observation, and to do so below command will be run.
duplicates report
After running the above command, below table will appear:
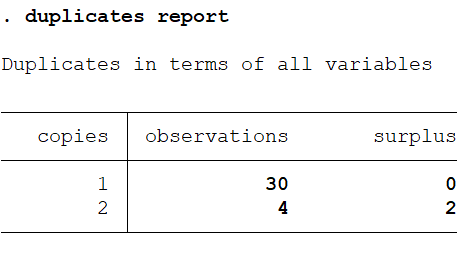
The above results show that 30 observations have 1 copy while 4 observations have 2 copies.
To determine how many repeating observations of symbol_code exist within the dataset, the below command will be run.
duplicates report symbol_code
After running the above command, the below results will be obtained.

According to the above results, 22 observations appear twice and 12 observations that appear thrice.
The above command uses for the cross-section data. However, in the case of panel data using the same command is wrong as it is a must to add a year variable along with symbol_code too. Therefore, to overcome that the below command will be run.
duplicates report symbol_code year
After running the above command, the below results will be obtained.

After running the above command, the above results will be obtained. According to these results, 26 observations are unique but 8 observations in cross-section and time data that are duplicates.
Listing the duplicate observations
Now to determine which observations are duplicates, the below command will be run:
duplicates list symbol_code year
After running the above command, the below results will be obtained:
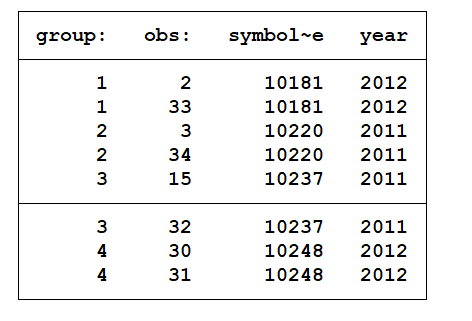
This table shows that 8 observations are repeating in the dataset.
Because the data is a panel, therefore, year variable has been used, too, along with symbol_code. However, in the case of cross-section data, the below command will be used:
duplicates list symbol_code
Dropping Duplicate Observations
We will run the below command to delete the duplicate observation.
duplicate drop

Running the above command, 2 observations will be deleted successfully that was duplicated. But still, the problem exists. The data include 4 duplicate observations, and only 2 observations are deleted. There are still 2 duplicate observations within the dataset; The reason is that cross-section and time series variables were not specified. So, the below command will be used to get rid of the duplicate value across the symbol_code and year.
duplicates drop symbol_code year, force
It is a must to provide the force option after the comma when specifying the variables within the command. Otherwise, it will give an error.
By running the above command, the rest of the 2 duplicate observations will also be deleted from the dataset.

Dropping Duplicates for a specific group
For instance, it is required to drop the duplicates of symbol_code 10248. In that case, the below command.
duplicates drop if symbol_code== 10248
First, we will write duplicate command then drop the command, and after that if the symbol_code will be specified as above.
The data before running the command looked like shown below:
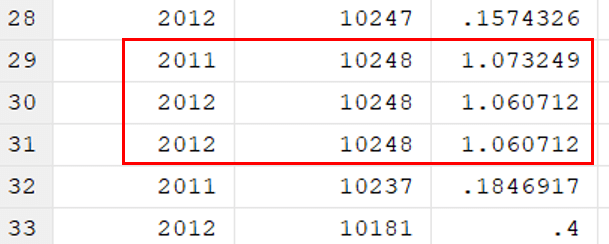
After running the command, the data will look like this. The duplicate observation of symbol_code was removed.
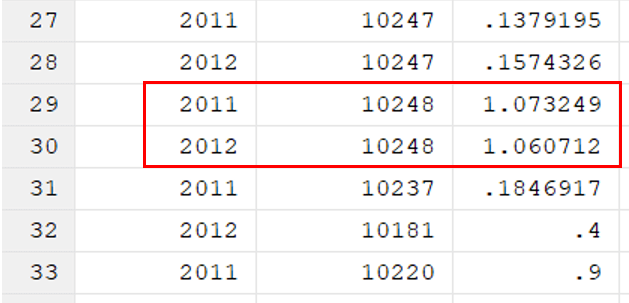
Tagging Duplicate Observations
Instead of dropping the duplicate, it is required to tag the duplicate observation. In that case, the tag command will be used after the duplicate command and then generate the new variable that will be named dup. Any name can be given in place of dup.
duplicates tag,generate(dup)
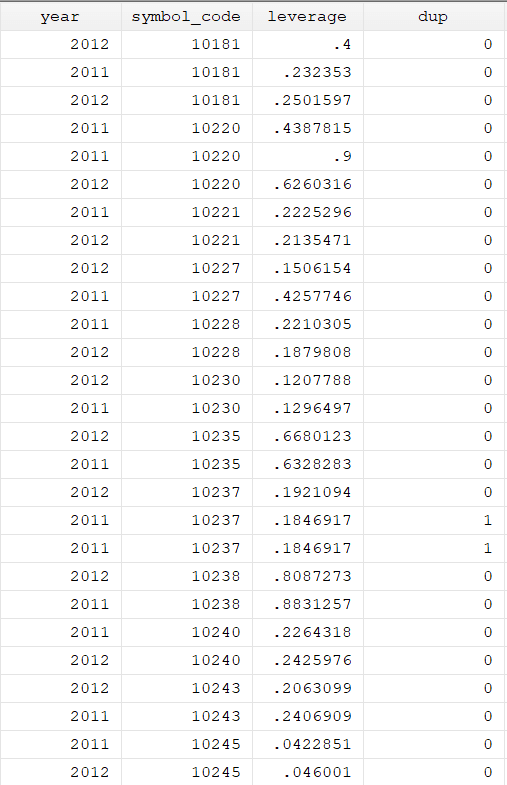
After running, this command the new variable will be generated named dup. This variable contains binary observation. 1 will represent the duplicate observation and 0 otherwise. However, the above command has an error, it does not specify duplicate observations across symbol_code and years. Therefore, to overcome that below command will be used.
duplicates tag symbol_code year, generate(dup2)
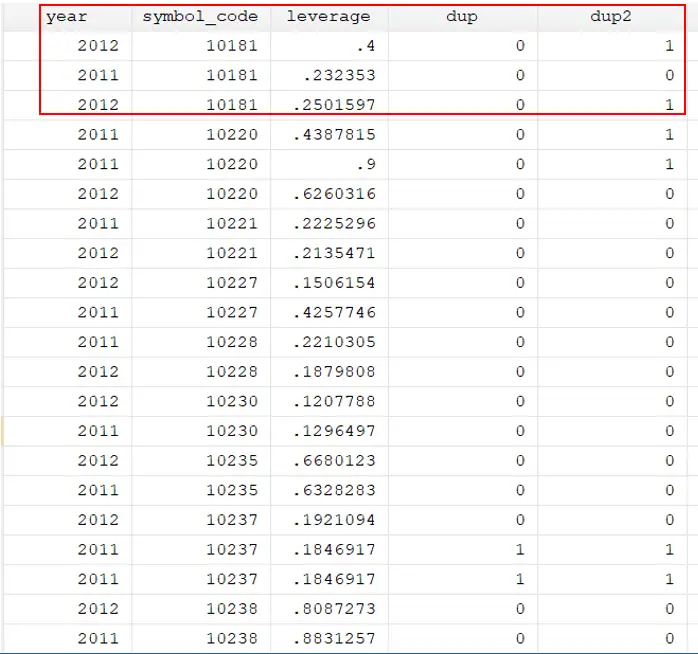
Now, it is required to remove the duplicate observation under a specific condition. For instance, instead of assigning 1 value to the duplicate observations and 0 otherwise, we want to assign 1 value to the duplicate value that occurred first and 2 to the second occurrence of the duplicate observation. To do that, the data will be sorted first using the below command.
sort symbol_code year leverage
Now, the new variable will be generated using the below command.
by symbol_code year: gen dup5 = cond(_N==1,0,_n)
After running the above command, the new variable will be generated.
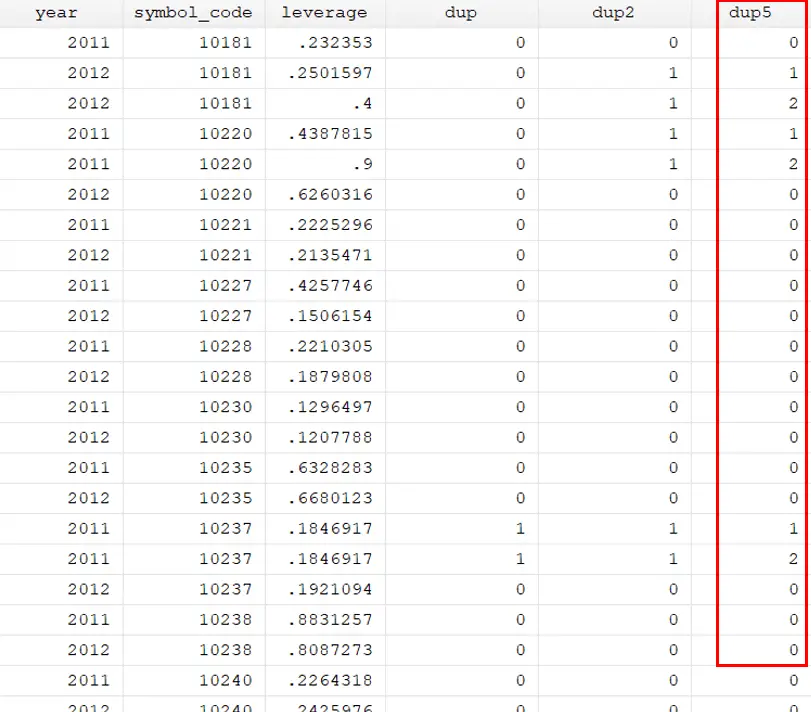
It can be noticed that 1 value is assigned to the first occurrence and 2 to the second occurrence. In this way, the duplicate value can be removed under that condition if dup5 ==1. It has known already that data is sorted the first occurrence is the lowest value of duplicate observation and the second occurrence is the highest value of duplicate observation.
The below path can also be used to report or list the duplicate observation:
Data > Data Utilities > Report and List Duplicate Observation
The duplicates can be removed below path:
Data > Data Utilities > Drop Duplicate Observation
Similarly, they can be tagged as well using the below path:
Data > Data Utilities > Tag Duplicate Observation