
While we are dealing with data analysis in R, it is essential to understand data structure and count number of observations by each variable or based on certain categories etc. This article deals with counting number of observations in diamonds data set. Before starting the article, first load the data set by using the following command
data(diamonds)
The diamonds data set has data for diamonds, including variables such as cut, color, clarity and price of diamonds etc.
Using Base R
Let’s calculate the number of observations using base R first. To calculate the number of observations in diamonds data set, we can use the nrow() function. This function will be used in a command in the following way
nrow(diamonds)
The nrow() function calculates the number of rows in the given data set, and returns the following output.

To get the total number of rows and columns in the data set, we can use the dimension function. The dim() function is used in a command in the following way
dim(diamonds)
This function returns the following output
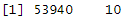
According to the above output, there are 53940 rows and 10 variables or columns in the data set.
In addition to the basic calculations of the total number of observations using nrow() and the total number of rows and columns using dim(), base R provides further flexibility for counting observations based on specific conditions and variables. The table() function, for instance, allows you to obtain a frequency table for a categorical variable.
The table() function can also be used to count observations of a variable as per category. To use the table() function for a variable, say, cut in the diamond data set, use the following command
table(diamonds$cut)
In the provided example, the table(diamonds$cut) command is used to display the distribution of observations across different categories of the “cut” variable in the “diamonds” dataset. This can be particularly useful for exploring the distribution of categorical data. The above command returns the following output, containing the number of observations for each category of the cut variable.
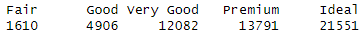
Moreover, the nrow() function can be applied with logical conditions to count observations that meet specific criteria. Let’s say we want to impose certain restrictions on cut and price of diamonds i.e. we want to count the number of observations where the “cut” is “Premium” and the “price” is greater than 236, you can use the following command.
nrow(diamonds[diamonds$cut == "Premium" & diamonds$price > 236, ])
This command creates a logical condition with the & (AND) operator to subset the data based on the specified criteria, and then the nrow() function is used to count the number of rows in the resulting subset. This approach allows for more nuanced exploration and analysis of the dataset by considering specific conditions. The result we get from the above command is following

Using Tidyvserse Package to count observations
Another way to count the number of observations in R is using the count() function in the tidyvserse package. The count() function is used to count observations based on one or more variables, with or without any restrictions. Let’s use the example of counting the number of observations for each unique value in the “cut” variable, but before that load the tidyverse set of packages by using the following command,
library(tidyverse) count(diamonds, cut)
This command will give the number of observations for each unique value of cut variable. Using the above command, we get the following results,

The results show that, there are 5 categories of cut variable, and each category has the different number of observations, as shown above. We can also sort the number of counts by using the following command
count(diamonds, color, sort=TRUE)
This will sort the categories in the descending order.

The count() function can also be applied to multiple variables simultaneously i.e. diamonds, color and clarity, to get the number of observations for these variables
count(diamonds, color, clarity)
The counts of observations will be displayed as per unique value of each variable, as shown below

We can also put certain restrictions/conditions to count number of observations for a variable. To put certain conditions to get count of observations, we use with() and sum() functions in combination.
sum(with(diamonds, cut == "Ideal" & color == "E"))
The above command restricts count of observations on two restricts that cut of diamond should be Ideal, and color of diamonds should be of E category.

The output shows that, 3903 observations meet the above specified conditions.
Another way to impose the same restrictions is using the filter() and nrow() function in the following way
nrow(filter(diamonds, cut == "Ideal" & color == "E"))
This will provide the same output as shown above.
Similarly, we can set a condition for the numeric variables to be equal, greater or less than a certain number in the following way.
diamonds %>% filter(price > 236) %>% count(color, name = "CountByColor", sort = TRUE)
The above command will give a summary table showing the count of observations for each unique value in the “color” column, considering only those rows where the price is greater than 236. The sort = TRUE argument ensures that the counts are presented in descending order. The output is given below

Whether using base R or the tidyverse, these techniques allow for a nuanced exploration of data, offering insights into variable distributions, relationships, and meeting specific criteria. By harnessing these functions, R users can efficiently extract meaningful information, contributing to a comprehensive understanding of their datasets.