
Drop and Keep commands are used for dropping or keeping the variables. These commands can also be used to drop values of certain variables. They both work somewhat similarly except for one difference these two commands are two phases of the same kind, i.e., you either drop certain variables or keep those variables.
For the sake of example, let us have a data set. For this data set we are using the Auto Data Set that comes preloaded with Stata, to keep things easier. Use the following command to load the data set
sysuse auto.dta,clear
Let us first figure out how to keep or drop variables. For this purpose, let us say that there is a variable called “make” to hint at the make or model of a car. What we can do with this variable is we can use the drop command and then type in the name of the variable to drop or delete that particular variable. Your command should look something like this:
drop makeDownload Example File
We can also delete multiple variables by just specifying the drop command and then listing the multiple variables. In this case, let us say that we have to drop three variables namely MPG, the repair variable, and the weight variable. Running the command as follows would drop all three of these variables
drop mpg rep78 weight
We can also use a fun kind of wild card which we can apply on a variable with a sequel. We have, let us say, sequels of price, i.e., price 1, price 2, price 3 and so on. So, all of these variables of price have some kind of a suffix. This suffix, along with the Wild card can be utilized to delete all of those variables that start with a certain character. To explain this phenomenon, let us just say we create a variable called “price2”, using the following command
gen price2=1
After making this variable, we have two variables namely “price” and “price2” and if we wanted to drop them both, there would be two ways. The inconvenient way is to list both of them separately for the command i.e.,
drop price price2

But the wild card way is to identify that both these variables have a common character which is a price. What can be done is that we can write the common characters and then specify a wild card i.e.,
drop price*
It would result in the drop of all the variables with the common character “price”.
Similarly, let us just say we have two variables that start with the letter “t” and we want to drop both those variables or all of those variables that start with “t”. For that purpose, we will be using the letter “t” and then the wild card, which would make the command look something like this:
drop t*
This would give the command to the starter to drop or delete any variable that starts with a t.
Using Keep command to keep certain variables
Along the same lines, we can use “keep” command that would keep specific variables while deleting the rest of them. In our scenario, let us say we have around five variables and we don’t need all of them rather we just need the length variable and the foreign variable for our analysis.
For that purpose, we are going to keep the length and the foreign variable. The following command would help us in doing so by keeping those two variables
keep length foreign
We can also switch it up and keep a single variable. For that, the method would be the same. We need to specify the keep command and name the specific variable. This would result in keeping that specific variable.
So the ultimate question is, should we use drop or should we use keep command. It depends on you because the board performs the same job except for a different path to complete that job.
So, the idea is that if you want to drop a few variables then you should use the drop command and if you want to keep a few variables then you should use the keep command. If, for example, we had around 15 variables and we wanted to keep some of the variables, let us say, three variables, it would be wiser to use the “keep” command to keep those three variables rather than writing the name of all those 15 variables and dropping or deleting them.
The idea is to use a smaller number or lesser names of the variables to ensure smooth, error-free and convenient operations. So, use drop if you want to drop a few variables and use keep if you want to keep a few variables.
Dropping values using keep or drop function
Moving on, we can also use the drop command and the keep command to drop certain values based on conditions. So let us say I want to delete the variables that show prices of cars to be greater than 12,000. The command would look something like this
drop if price> 12000
This would result in execution of the said command, as shown below.

Mind you, previously we were working on dropping variables that were represented in columns in the data set. Thus, columns were deleted in our previous operations. Now, however, as we are working with conditions, we are dropping rows that fulfil those conditions i.e., prices of cars that are greater than 12,000 need to be deleted or dropped.
Needless to say, this would not drop the price variable but rather it would drop all those values and all those rows that meet our specific and certain condition, in this case it is price is greater than 12,000. Subsequently, from the command window we can see that once we perform this command, five observations have been deleted. This shows that there were five rows that had price greater than 12,000.
Now, what if we wanted to keep all those variables that have their prices less than ten thousand. For this, similarly, we would be keeping rows rather than keeping the variable. Keep in mind that if you specify a certain condition, it will work for the rows. It can either drop or keep the rows. Refreshing our memories, if we just specify the command drop along with the variable name, it will result in deletion of the columns or the variables. Returning to our point, let us keep all those cars that have prices less than 10,000. The command will be as following
keep if price<10000
As we know, there are five observations that were deleted previously. Just to clarify, we can also use multiple conditions. Under the light of this knowledge, we can keep or drop values based on multiple conditions and for the sake of example, if we wanted to drop all those rows where the price is greater than 5000 and the mileage is equal to 22, our command would look something like this:
drop if price>5000 & mpg==22
We can use other logical indications as well. We can use “or” condition as well. That means that if you want to change the condition for the command from “and” to “or”, you need to slightly change the command. So the previous command, with this change would look something like this:
drop if price>5000 | mpg==22
Let us take a fresh example to understand this concept better,
drop if price>9000 | mpg==22
The above can be translated as: drop the rows that have prices greater than 9000 or have mileage equal to 22. This means that either the 1st condition should be met, or 2nd condition should be met. Thus, all those rows and all those cases and observations where either price is greater than 9000 or mileage is equal to 22 would be dropped.
Drop or Keep Missing Values
Moving ahead, we can also drop or keep missing values. Let us summarize our data using following command
summarize
From the observation column we know that all those variables that we have in our data set have a total number of 57 observations except for one repair variable which has 54 observations.
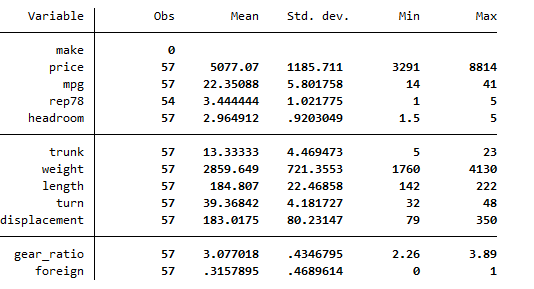
When we look at the data for this repair variable, we can see that there are certain dots in them.
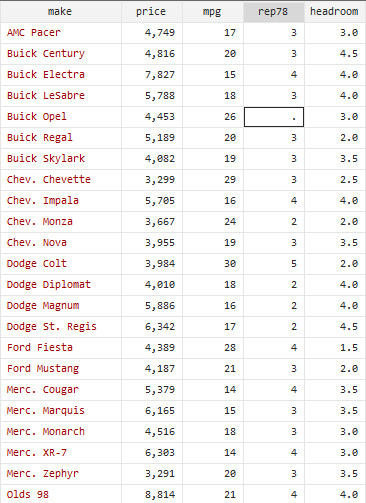
In the language of Stata these dots indicate missing values. So if we want to drop these missing values, what we would do is to customize our command as such
drop if rep78 ==.
Be careful of not losing the dot in this command as it would be the core of this command and would help you in dropping all the missing values. By looking at our data set, we can see that there were three observations where rep78 was missing. By quickly summarizing, we would know that we have only 54 rows as opposed to 57 rows. That’s how simple it is
We can also use the drop if missing function, which simply suggests dropping all the rows where the specific condition is missing. For the sake of example, our command
drop if missing (rep78)
This would drop all the rows where the rep78 has certain missing values. So, if you do not want to use the dot explicitly, you can use the missing function. Using the missing function is better for certain reasons.
We can also use the keep command instead of the drop command, which can help us in keeping all those values where the rep78 is missing. Subsequently, we can use the missing function in the similar fashion as shown previously. Both the commands
keep if rep78==.
and
keep if missing(rep78)
work the same way, so it is up to the user to either use the syntax or use the command.
Moreover, we can drop in certain range and when what we mean by range is a certain number of cells. What we can do is that we can write our command as such:
drop in 1/10
This would drop the first 10 rows; starting with the 1st row and ending on the 10th row. If you are keen, you would notice that all these 10 rows would be dropped from your data set.
We can also use the keep command to just keep the first or the last value in a panel data. For that purpose, we are going to use a different data set. Load the following data set
Let us say that we have a stock prices data which shows different firms in a column. All these firms have their years and their stock prices. So what if we wanted to keep the rows for each firm where that specific firm have a highest year. For the sake of example, the first firm has the highest year is 2017 but for firm 2 the highest year is 2015 and for the third firm the highest year is 2019. It is clear that we just want to keep the highest year of these firms. what we will do is that use the command
bys firm: keep if _n==_N
This command is attempting to explain that we are commanding to keep the values if the number of observations is the highest. We are trying to comprehend that we have a panel data but beware, we need to repeat this command for each firm.
If you need to understand the difference between the small ‘n’ and the bigger ‘N’ refer to our article.
So, with this command, it should keep 2017 for the 1st firm, 2015 for the 2nd firm and 2019 for the 3rd firm.
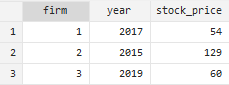
We can also do it in the opposite way, that is to keep the smallest year for each firm with this command:
bys firm: keep if _n==1
Consequently, for the 1st firm, the year would be 2010, for the 2nd firm, it would be 2005 and for the 3rd firm the smallest year is 2016.
Our command
bys firm(year): keep if _n==1
can also have a space to use the year in the bracket. This would perform this command for each firm by years. However, before performing this command one should sort the data in years, consequently. We already have that sorted, but in case you do not have the data sorted you should use the command,
sort firm year
before using the first command. Thus, we want Stata to sort the data based on firm first before we perform any other command.
We can also drop all the variables with the command:
drop _all
But remember, this is different from Clear command. Clear removes macros or any value labels but drop all only deletes the variables. To understand what this would mean, let us create a variable, conveniently called,
gen price=.
We just created a variable, so we can use the variable manager. Now, if we go to Value labels, we can see that there was a value label that was assigned to our foreign variable. That value label is still there. If we had used the “clear” command, this value label would have been gone but because we had used the “drop
_all” command, it does not clear the variables but rather drops it.
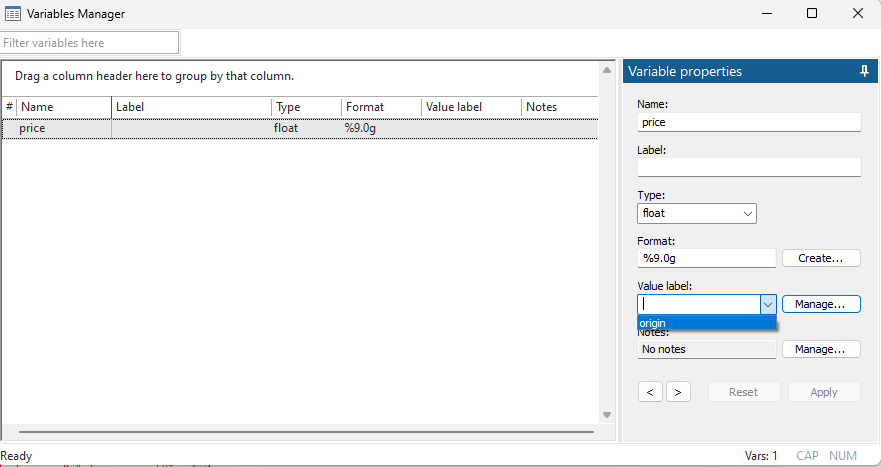
To move forward, let us just quickly use
clear
Now generate the price variable using following command
gen price=.
Now if we back to the variable manager, and now we will be able to see that value labels have been removed. So, in a nutshell, clear would delete everything from the environment, not just the variables and the data but also all the other elements that had been created during the process.
we can always use the menus, obviously, for drop and/or keep commands. If you want to drop variables then we can click on “data” from the menu bar and from “data” we can click over on the “variable manager”. If you want to drop observations, then can go to “data” to “create or change data” and “drop or keep observations” to get desired results.
Lastly, please do remember that once you have dropped a variable or an observation, you cannot go back. Undoing that would not be possible. It is better to remember to use either “frame” or “preserve” command before you drop certain variables. This would help v you in the case that you want to go back to the original data set. Happy Learning!